-
Why are people so scared of causing fear?
An odd aspect of discussing serious threats is the amount of concern people express about you causing other people to be concerned. This kind of makes sense for interlocutors who don’t believe in the threat itself, or think it is overblown (though in that case it is perhaps strange to focus on altruistic concern for potential frightened onlookers rather than the object-level disagreement). But often the person is not actually disputing the threat, they purportedly just want to protect the public from fear, or avoid causing ‘panic’.
A memorable case: on what was to be one of the last normal weekends in 2020, I took an Uber with a friend to an event. On the way we discussed the rising warnings of an international pandemic and our preparations. But my friend wanted us to talk more discreetly, lest we scare the Uber driver.
Why on Earth would it be bad to scare the Uber driver? My friend believed as much as I did that a real and deadly virus was spreading and there was an imminent risk of this affecting us all, including the Uber driver. Didn’t the Uber driver have an interest in knowing about it? Wasn’t it, if anything, our responsibility to tell the Uber driver? Is the concern that, as a normal person, the Uber driver is incompetent to manage himself, and will just scream and run around or buy poorly selected prepper equipment?
In conversations about AI risk, I sometimes see the same thing. Geoffrey Hinton says he thinks there’s a 10-20% chance of human extinction, and some people seem genuinely most concerned is that maybe the press didn’t add enough disclaimers about the process by which he reached that number, and the public may get unnecessarily worried. I agree it would be non-ideal if people were 20%-level worried when they would only endorse being 7% worried on further methodological inspection. But among non-ideal aspects of a situation where most of the relevant scientists believe their field is heading toward a modest-to-strong shot at killing us, it’s interesting to rate “maybe people will be too concerned” as a top concern.
What is going on? In this particular case, I could imagine behaving this way if the original communication seemed dishonest. But finding this dishonest seems similar to complaining if someone yells “fire!” that they should have yelled “I subjectively guess that it’s highly likely there’s a fire because of the smoke and flames but I’m not an expert”. And it seems like there’s something else going on with wanting that.
A related phenomenon: people casually mention ‘causing a panic’ as a thing that is assumed to be too terrible. Like, yes there’s some upside to warning people that there is a major threat to their lives that they can do something about. Maybe doing that will help stop the world from ending. But! What if they get all emotional? They may not act in the most clear-eyed and rational way. They may talk to each other in epistemically unvirtuous fashions and get even more concerned. They may buy too much toilet paper or run on a perfectly functional bank or protest for poorly designed policies.
I mean, indeed this is all worse than them addressing threats in the most rational and optimal way. But how is it a problem that even ranks compared to them not addressing threats because they don’t know about them? And who are you to not tell people about genuine risks to them that they would act on, to protect their feelings or because they would be more upset than you want?
-
Women should be able to open things
m pretty annoyed today, for nominal reasons ranging between ‘petty’ and ‘doesn’t even make sense’. I’m not entirely sure how or if to take oneself seriously when one has such absurd grievances. But that’s a question for another time—I’m here now to tell you about my one potentially valid peeve.
I understand that gender is complicated and difficult, for the whole species (and honestly probably more so for some other species). And it can be hard to tell exactly if anyone is behaving badly regarding it, at least in my modern bubble. Maybe women just aren’t that into designing programming languages? Maybe the thing I’m saying is just boring and a man is saying a more interesting thing?
But a thing that is undeniable is that women want to open jars, dammit! What’s your nuanced explanation there, Bonne Maman? Does the proper amount of friction for maintaining spread safety fall just between the male and female human grip strength distributions?
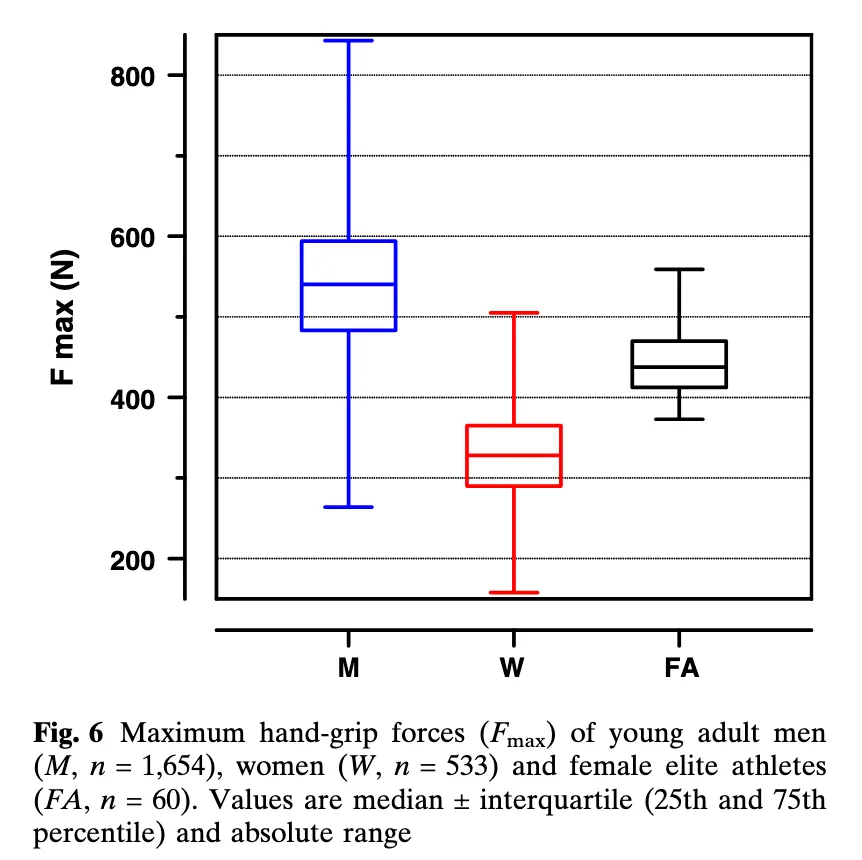
This study suggests that would be about 400N Fmax (though this would not avert most elite female athletes acquiring jam, see second figure, and the pictured participants are young adults):
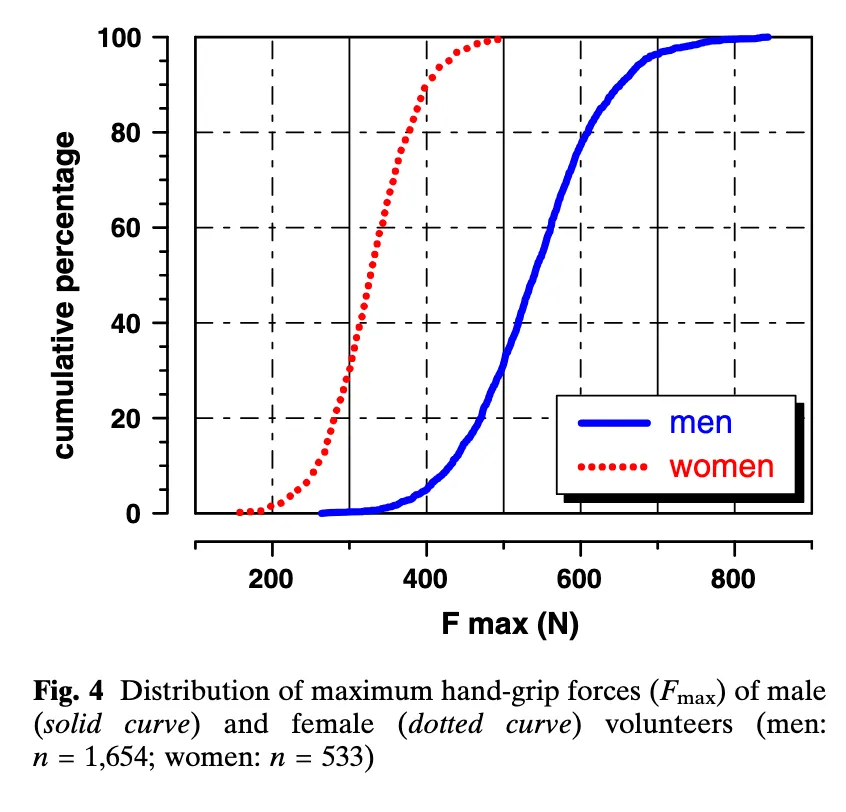
The distributions are really surprisingly not-overlapping!
90% of females produced less force than 95% of males. Though female athletes were significantly stronger (444 N) than their untrained female counterparts, this value corresponded to only the 25th percentile of the male subjects.
We know that men and women have different grip strengths! We know that about half of people are women! Why do so many containers require women asking a man for help in order to open them? (Or carrying around an opening tool or living in a kitchen?)
Yes, strength required to open packaging ranges across a wide distribution, but I note that very few are impossible for anyone to open, so it seems like some effort somewhere goes into keeping them in the feasible range, and that effort does not seem to care about it being reliably feasible for people like me. I don’t imagine Bonne Maman wants to stop women getting to their jam—I imagine that nobody cares.
I thought about this most when I lived in a group house with a shared bulk stash of Gatorade, and any time my woman housemate or I wanted to drink a red one we’d have to ask a guy to open it for us. But these days I also often hurt my hands opening (or failing to open) things, and while I’m sure I’m low in the female grip strength distribution—and may also be high on the ‘unreasonable anger about anything nearby when my hands are hurt’ distribution—I don’t think it’s just a me issue, and in the moment it always feels like a ‘fuck you, raspberry jam isn’t meant for you’.
-
Numb mental state shifts
There are different mental states that feel different. Those are relatively obvious. For instance, being angry or drunk or frustrated or besotted.
Then—for me at least—there are different mental states that don’t immediately feel like anything, but where in acting I notice that my behavior is different, or different things feel easy or impossible. For example:
Continue reading → -
Understand why AI is a doom-risk in 39 captivating minutes
I’ve really wanted more good short accounts of why AI poses an existential risk. Working on one myself has been one of those incredibly high priorities I keep putting off.
Meanwhile award-winning journalist Ben Bradford of NPR has made a podcast version of my case for AI x-risk that I am thrilled with!
(Bonus within the 39 minutes: what Hamza Chaudhry of FLI thinks we should do about it—who I was delighted to later meet as a consequence!)
If you or anyone you know could do with a quick and gripping rundown of why this is a problem, try this one.
Get it on any podcasting app here: https://pod.link/1893359212
Continue reading → -
Games that change your mind
Some things you might learn from games are pretty blatant: Trivial Pursuit might teach you trivia, MasterType might teach you about typing, Grand Theft Auto might teach you about driving or crime.
But sometimes games teach people less obvious things—things that are more experiential or ineffable, things that you didn’t know you didn’t know, concepts that stick in your mind, deep things. Here’s my list of games and their interesting real-world updates, as experienced by me or my friends:
Dominion: Don’t invest for eternity. When casually improving or protecting or investing in things, it’s easy for me to treat life (and perhaps even the present period) as basically eternal. In fact I shouldn’t, but it can take many years of living to really feel how likely it is that you’ll leave your perfectly wonderful house within two years, or just keep on aging. Dominion lets me feel that in a matter of hours, by tempting me to invest in a beautiful and effective deck that will do amazingly for the rest of eternity, then making the other player win by haphazardly buying a handful of provinces before I’m done. Which is very annoying, and I do hold against it.
Continue reading → -
11 ways to be less deferential
often worry that people are being too deferential about their beliefs. I also hear others worrying about this, and nobody seemingly worrying about the reverse, except perhaps my friends and therapists (and I guess honestly people who know cranks, so that’s a bit troubling).
Which leads me to wonder, supposing it’s true that many people are too deferential, what might people do to change it? And can I offer them useful advice, as a person who might be not deferential enough?
Tonight I talked to Joe Carlsmith about this; here are some ideas mostly from the conversation:
Continue reading → -
Self driving interview
In honor of yesterday’s nonspecific point in the gradual arrival of self-driving cars, an interview with myself.
Continue reading → -
San Francisco: self driving
I’m on a plane heading back to San Francisco. I’ve lived in the Bay Area for most of the years since 2009, and a large fraction of that time the place has felt near the brink of self-driving cars. (Well, everywhere has, but San Francisco feels like the first testing ground for the most interesting experiments in technology.) And that has felt like a big deal. So I kind of expected them to arrive with a good amount of ceremony.
Continue reading → -
AI unemployment and AI extinction are often the same
My sense is that people think of AI existential risk and AI unemployment as distinct issues.
Some people are extremely concerned about extinction and perhaps even indifferent to total unemployment. Some people think of moderate AI unemployment as a realistic and concerning issue, and AI extinction as science fiction.
I think of AI unemployment and AI extinction risk as basically the same issue, and in likely scenarios, happening together.
Continue reading → -
Manhattan: distance and movement
Last Tuesday I went to a Broadway show, Ragtime. I was in the front row, but surprised by how much the action did not feel real and a few feet away from me. Perhaps the performers were so skilled they didn’t seem like real people, or the sound so loud and sharp that it didn’t feel like people legit singing just over there. We seemed to have a proper chance of getting spit on us, yet I felt as if I was in a separate world. The biggest break in the feeling of vague unreality was when one of the actors on my side of the stage made piercing eye contact with me for a second or so. Which felt very close and warm and human, and I was kind of thrown by that too, though I liked it.
Continue reading →
EVERYTHING — WORLDLY POSITIONS — METEUPHORIC