-
Why are people so scared of causing fear?
An odd aspect of discussing serious threats is the amount of concern people express about you causing other people to be concerned. This kind of makes sense for interlocutors who don’t believe in the threat itself, or think it is overblown (though in that case it is perhaps strange to focus on altruistic concern for potential frightened onlookers rather than the object-level disagreement). But often the person is not actually disputing the threat, they purportedly just want to protect the public from fear, or avoid causing ‘panic’.
A memorable case: on what was to be one of the last normal weekends in 2020, I took an Uber with a friend to an event. On the way we discussed the rising warnings of an international pandemic and our preparations. But my friend wanted us to talk more discreetly, lest we scare the Uber driver.
Why on Earth would it be bad to scare the Uber driver? My friend believed as much as I did that a real and deadly virus was spreading and there was an imminent risk of this affecting us all, including the Uber driver. Didn’t the Uber driver have an interest in knowing about it? Wasn’t it, if anything, our responsibility to tell the Uber driver? Is the concern that, as a normal person, the Uber driver is incompetent to manage himself, and will just scream and run around or buy poorly selected prepper equipment?
In conversations about AI risk, I sometimes see the same thing. Geoffrey Hinton says he thinks there’s a 10-20% chance of human extinction, and some people seem genuinely most concerned is that maybe the press didn’t add enough disclaimers about the process by which he reached that number, and the public may get unnecessarily worried. I agree it would be non-ideal if people were 20%-level worried when they would only endorse being 7% worried on further methodological inspection. But among non-ideal aspects of a situation where most of the relevant scientists believe their field is heading toward a modest-to-strong shot at killing us, it’s interesting to rate “maybe people will be too concerned” as a top concern.
What is going on? In this particular case, I could imagine behaving this way if the original communication seemed dishonest. But finding this dishonest seems similar to complaining if someone yells “fire!” that they should have yelled “I subjectively guess that it’s highly likely there’s a fire because of the smoke and flames but I’m not an expert”. And it seems like there’s something else going on with wanting that.
A related phenomenon: people casually mention ‘causing a panic’ as a thing that is assumed to be too terrible. Like, yes there’s some upside to warning people that there is a major threat to their lives that they can do something about. Maybe doing that will help stop the world from ending. But! What if they get all emotional? They may not act in the most clear-eyed and rational way. They may talk to each other in epistemically unvirtuous fashions and get even more concerned. They may buy too much toilet paper or run on a perfectly functional bank or protest for poorly designed policies.
I mean, indeed this is all worse than them addressing threats in the most rational and optimal way. But how is it a problem that even ranks compared to them not addressing threats because they don’t know about them? And who are you to not tell people about genuine risks to them that they would act on, to protect their feelings or because they would be more upset than you want?
-
Numb mental state shifts
There are different mental states that feel different. Those are relatively obvious. For instance, being angry or drunk or frustrated or besotted.
Then—for me at least—there are different mental states that don’t immediately feel like anything, but where in acting I notice that my behavior is different, or different things feel easy or impossible. For example:
-
If I’m in a lot of pain or distress alone, I might feel like I couldn’t compose myself. But in fact if company shows up, it becomes natural to pull myself together.
-
If there’s a time limit, I will often find a vast well of motivation that was otherwise non-existent. The day before a deadline I will smoothly (if with a lot of effort) do ten times as much as on a normal day.
-
On some days at least, if it’s 8pm, things will become possible that I could only have dreamed of at 11am.
-
Riding my bike to the station, then taking it on the subway, then riding it again to get to a party seems like not a big deal with a friend, but like a prohibitive ordeal on my own.
Some of these are very important! For instance, in causing myself to get ten times as much work done sometimes, or to travel to places, or to not despair if things seem impossible at 11am.
But how many more shifts like this do I never notice because I don’t probe the range of relevant behavior in every possible circumstance? If different humans have similar mental architectures in this regard, can I get a list of the common ones somewhere?
-
-
Understand why AI is a doom-risk in 39 captivating minutes
I’ve really wanted more good short accounts of why AI poses an existential risk. Working on one myself has been one of those incredibly high priorities I keep putting off.
Meanwhile award-winning journalist Ben Bradford of NPR has made a podcast version of my case for AI x-risk that I am thrilled with!
(Bonus within the 39 minutes: what Hamza Chaudhry of FLI thinks we should do about it—who I was delighted to later meet as a consequence!)
If you or anyone you know could do with a quick and gripping rundown of why this is a problem, try this one.
Get it on any podcasting app here: https://pod.link/1893359212
The NPR press release has more context on the rest of the series, assessing different possible sources of doom.
-
Games that change your mind
Some things you might learn from games are pretty blatant: Trivial Pursuit might teach you trivia, MasterType might teach you about typing, Grand Theft Auto might teach you about driving or crime.
But sometimes games teach people less obvious things—things that are more experiential or ineffable, things that you didn’t know you didn’t know, concepts that stick in your mind, deep things. Here’s my list of games and their interesting real-world updates, as experienced by me or my friends:
Dominion: Don’t invest for eternity. When casually improving or protecting or investing in things, it’s easy for me to treat life (and perhaps even the present period) as basically eternal. In fact I shouldn’t, but it can take many years of living to really feel how likely it is that you’ll leave your perfectly wonderful house within two years, or just keep on aging. Dominion lets me feel that in a matter of hours, by tempting me to invest in a beautiful and effective deck that will do amazingly for the rest of eternity, then making the other player win by haphazardly buying a handful of provinces before I’m done. Which is very annoying, and I do hold against it.
**The Witness: **there is nothing in The Witness (at least near the start, I haven’t played it all) that you can pick up and take with you. No objects, no points, no manna, no health. It’s just you, walking around in a world. Something about that feels like it would be deeply unsatisfying—like what is a game, if you can’t get, y’know, things, dings? Part of me thinks that GETTING is equivalent to satisfaction, in spite of all the evidence to the contrary I keep pointing out to it. And The Witness is not where I came to realize that. What The Witness made me feel is that knowledge is a REAL thing you can GET, like an object. Not some hand-wavey second-rate bullshit thing that philosophers pretend to get off on. In The Witness, while your character walks around, impermeable to the world, you come to know more things. And knowing more things lets you go to places you couldn’t go to when you knew fewer things. The game on the computer concretely changes from you picking up knowledge, that ethereal thing in your mind. This is of course how everything is, but I suppose the absence of any other form of ‘picking up things’ in The Witness made me actually feel it.
**Minecraft: **How many of my difficulties in life are not this-life specific. How to live as a creature with different boundaries of personal-identity, e.g. the world spirit. Much more about these in my previous post, Mine-craft.
Return of the Obra Dinn: If at an event where lots of people are saying their name and what they do or something, I am usually bored and don’t expect to remember these things. Return of the Obra Dinn is a game where you have to figure out from minute clues the names and causes of death of a lot of characters. Once at a networking event, I decided to think of it as like a sequel of Return of the Obra Dinn—I could see all these people sitting around the table, and my quest was to pin a name and a deal to each of them, and this introductory section was currently showing me crucial information. I found that this was a very different mental state. So I suppose I learned that whatever I was normally doing in ‘trying to learn’ things about the other attendees, it is an extremely pale cousin of the curiosity I can feel in a different mental state, and that different mental state is actually fairly different, and naturally invoked in RotOD and not networking introductions.
**Dungeons and Dragons: **Caitlin Elizondo says DnD has given her a few concepts that make a difference to her thinking more generally. The concept of ‘will saves’ has given her more empathy for situations where someone wanted to but failed to do something. The six DnD stats helps her access the framework where there are different types of competency that are valuable for different tasks—obvious in theory, but easier to think in terms of with this structure.
**Poker: **the feeling of being ‘on tilt’
Boggle, Set, Ragnarock: the feeling of flow. Ragnarock is mine, and I would have said I’d experienced ‘flow’ elsewhere, but Ragnarock is sometimes more like an altered state than other such experiences I’ve had.
Civilization IV: I used to lose at a scenario then go back and play it again over and over changing things slightly until I won, which gave me a vivid sense of how suboptimal my native strategy is, presumably also in life. Which is obvious in theory, but it’s different to really feel how much better I would live this day if I was doing it the twentieth time with a laser focus on winning.
Games in general: the experience of addiction, sadly. I’ve always struggled to keep up habits of taking addictive substances, so I infer I’m unusually safe from chemical addictions (I used to play Civilization for five minutes as a reward if I remembered to take my amphetamines). Games are I think the thing I find most seriously addictive. Which has definite downsides, but it is certainly also an interesting experience that helps me understand the wider world better, and where I would be missing something if I just read about addiction in the abstract.
Do you have any to add?
[ETA May 1: I’m adding more I hear in the above list, and also see many good additions in the comments!]
-
11 ways to be less deferential
often worry that people are being too deferential about their beliefs. I also hear others worrying about this, and nobody seemingly worrying about the reverse, except perhaps my friends and therapists (and I guess honestly people who know cranks, so that’s a bit troubling).
Which leads me to wonder, supposing it’s true that many people are too deferential, what might people do to change it? And can I offer them useful advice, as a person who might be not deferential enough?
Tonight I talked to Joe Carlsmith about this; here are some ideas mostly from the conversation:
- A thing that has discouraged me from having independent views and broadcasting them is the concern that my views are extremely ignorant. At the normal pace of new information appearing, I am just too slow a reader to be acceptably up on it. At the AI-news rate, it’s very hopeless. And even if you recognize that situation at a high level, it can be easy to get to thinking ‘I want to write something about W, but I’ll need to read X, Y and the sequence on Z and all the responses to it first’.
It was helpful to me to give up on this kind of expectation, and accept that I’m going to be ignorant and have views anyway. I think this is the right thing to do because a) everyone is fairly ignorant and we don’t want the public discussion to be only the few people who don’t realize they are ignorant or care, and b) saying what you guess is true then letting people point you to why you are wrong is often more efficient than scouring all writing on the topic, and c) there’s value from more independent thinking on a topic, and being informed comes with being less independent. Bringing us to—
-
Being sufficiently out of the loop can actually help, as long as you are bold enough not to be silenced by this—if you don’t know what others’ views are, you have to come up with your own.
-
Focus on having your own beliefs at a relatively high level. For instance, “Shouldn’t we be stopping AI though?.. Wait, does that argument make sense?” is the kind of thing you can think about and discuss reasonably well without needing to know a lot of technical or fast-moving details, until a more manageable few are brought up in the argument. And my sense is that these kinds of questions—e.g. is our basic strategy what it should be?—are actually neglected.
-
Which brings us to status. Intellectual deference probably follows normal patterns of status-based deference. So it probably helps to be either high status or arrogant. That’s a lot of effort, but you can have the experience of being high status or arrogant by talking to people who are relatively lower status or deferential, such as children.
-
It probably helps to be brought up in a situation where you learned to distrust the thinking of everyone around you. It’s probably ideal to be taught by your parents that everyone else around is an idiot, then to come to distrust your parents opinions also.
-
That’s hard to get later in life. But perhaps you can get something similar from experiencing apparently venerable intellects confidently asserting things, then later observing them to be false.
-
If you are in conversations where it seems like the other person isn’t making sense, try to assume that is what’s going on, rather than the potentially much more salient explanation that you are a fool.
-
Give esteem to people asking potentially silly questions. It can help to expose yourself to impressive people who do this.


Niels Bohr quotes are helpful (HT Wikiquote)
-
Refuse to ‘understand’ things unless they are very clear. I don’t really know how to do this, because I don’t know what the alternative is like—being steadfastly confused about things seems to come naturally to me and I don’t know how else to be, but maybe you have both affordances available here and could lean one way or the other.
-
Something something do real thinking versus fake thinking. Ironically, this point I am deferring on, because I haven’t finished listening to Joe’s (so far very interesting) post.
-
If you are going to pass on information that you don’t deeply understand, track that it is a different thing, for instance by saying ‘something something…’
-
AI unemployment and AI extinction are often the same
My sense is that people think of AI existential risk and AI unemployment as distinct issues.
Some people are extremely concerned about extinction and perhaps even indifferent to total unemployment. Some people think of moderate AI unemployment as a realistic and concerning issue, and AI extinction as science fiction.
I think of AI unemployment and AI extinction risk as basically the same issue, and in likely scenarios, happening together.
At a very high level, I’d say the argument for human extinction from advanced AI is something like this:
We’re going to make AI that can do everything better than humans
We’re going to make that AI into agents that navigate the world independently and do what they want
We are not going to make those AI agents want the right things
The basic issue is that in the presence of more capable agents with different goals, humans are less able to get resources and influence, and direct them toward the humans’ goals.
One way ‘losing power to more competent agents’ could look is that a surpassingly smart AI agent intentionally eradicates humanity. But killing everyone and controlling the world is a pretty wild corner case of ‘using your competence to control the situation toward your own preferences’. In particular, it has never been seen before, though the new AI situation might make it possible.
The traditional ways that humans make use of competence to influence the world include earning salaries then spending the money on things they want, earning investment income, making and using alliances, persuasion, taking political actions, etc.
If no ultrapowerful AI appears and exterminates us, I think we have every reason to expect ruin from AI sapping our power and resources by these more traditional methods. Outcompeting us as labor, outcompeting us as informed capital holders, outclassing us at political strategy and persuasion, and controlling the conversation.
It’s true that if humans were only excluded from the employment path to resources or influence, this would merely be an excruciating upheaval on a massive scale, and probably not herald extinction.
But unemployment here is just the most legible tip of a sprawling shitberg. It’s just not plausible that humans are unemployable, but they are doing well at political strategy and persuasive communication. Unemployment goes with losing power across the board, except insofar as power is granted by whoever has it by virtue of might. That is, insofar as AI cares about empowering us.
So unemployment could happen without extinction (if we successfully built AI that cared about us in the right way) and extinction could happen without unemployment (e.g. if an extremely competent AI system decides to exterminate us). But in a lot of cases they not only coincide, but are the same issue.
Asking if someone is more concerned about unemployment or extinction is like asking if someone primarily wears a seatbelt when driving to avoid having their body flung through the windscreen, or to avoid dying.
If powerful AI agents have their own agendas, those agendas will win out. They might win out in one crushing step, or win out in a trillion small familiar ways.
-
How much should the ideal person cry wolf?
It is a fact about wolves and rationality that you should warn people about wolves quite a few times for every effective wolf attack.
In particular, there is an asymmetry between the costs of having one’s flock devoured and averting a non-eventuating wolf attack. If the carnage is a hundred times worse, then it’s worth up to ninety-nine false alarms to stop it.
The original fable was about a boy who would continually lie about wolves, and that is definitely poor form.
But in modern parlance, ‘crying wolf’ seems to be used for just being openly alarmed about things that turn out ok—I don’t hear much implication of deceit.
And in modern sensibilities, being seen to ‘cry wolf’—by even once raising an alarm that isn’t consummated with disaster—is something people seem to really fear. I think multiple people have asked me about whether AI safety people might have ‘cried wolf’ about some earlier GPT model. I’m not aware of anyone doing that, but the idea that they might have is so tantalizing that it bears investigating. Because if even a a few people somewhere did, it would be such a nice embarrassing blow to AI safety people.
And I probably responded in the tempting way: jumping to assure that I don’t recall hearing any such fears from these quarters. But I think that worsens public thought norms by implicitly buying into the unspoken premise that it would be quite shameful and naive to have raised even one warning.
And so relatedly, probably people who see real risks from AI are scared to voice them, lest they be seen to ‘cry wolf’ and tank the credit of the movement for the next round of dangers. Because it is taken for granted that one should only get one chance to raise an alarm. That the first warning must be for the most undeniably big, bad, real wolf.
This is not the wolf lookout system we want.
‘Warnings’ are usually about fairly bad events, and therefore they tend to be worth making when the probability of those events is still low. This creates a real difficulty for society in adjusting people’s credit when the low probability events they have warned of do not come to pass. Most of the time, if the person is right, the events still shouldn’t happen! The person wasn’t saying they were likely! Yet you don’t want to let the alarmist off the hook, with plausible deniability for arbitrarily many alarms.
I think the solution to this difficulty should look much more quantitative, like collecting rich track records of the predictions made by a person or a movement, and scoring them well. The present solution of childishly denouncing any unmet danger is insane.
And meanwhile if there are bad risks that have a low chance of appearing on every warning, we should still warn of them, and not be too much cowed by innumerate customs.
-
Vibe signaling externalities and the people-to-places pipeline
People are sending signals all the time, and those signals are to my knowledge usually about themselves: they are smart, or kind, or attractive, or not naive, or have their shit together, or care about Palestine, or care about you, or are friendly, or artsy, or professional, or relatively in the know about the cultural currents of TikTok or DC.
People are also taking in signals all the time, and these signals are often about other people, and often even closely related to the signals being intentionally sent: Alice is trying to seem friendly, and Bob perceives her as friendly. But also a lot of signals people take in are about places. People read places as safe or dangerous, lighthearted or depressing, silly or serious, asking them to know more, or get more power, or do more. Suggesting they laugh drunkenly under the moonlight, or get up at 5 and pray. Encouraging submission or rebellion.
These signals that make the world feel one way or another make a big difference to people. They make one neighborhood nice to live in and another feel off, one workplace energizing and another deflating. But they are—to my knowledge—almost entirely unintentional side effects of the ways people behave for other reasons. People don’t dress nicely to collaborate in making you feel like you are in a thriving part of town. They dress nicely to make someone think something about them. And someone probably does, but then the signal is left there for everyone else to sweep into their average perception of the vibe in this part of town.
A lot of ways people behave that affect the vibe are probably not intended as signaling at all—for instance, perhaps I grow roses in my front garden because I love roses, and it nonetheless affects people’s read of the vibe. Or perhaps I keep piles of scrap metal there because I want them for something, and that has a different effect.
But an interesting dynamic to me is that a lot of efforts are going into sending signals about people, and those signals are being read as messages about places. Because places can’t send their own signals, but vibes are a very big part of how people experience places, and place vibes are heavily influenced by people’s attempts to paint themselves as one thing or another.
People try to look not-to-be-messed-with and strangers read the street as dangerous. People try to look generative and strangers read the neighborhood as wealthy enough to have time for this. People try to look rich and people read the area as safe. People try to look beautiful and people read the scene as shallow. People try to look smart, and people read the office as unwelcoming.
In sum I posit that there are massive externalities in vibes, and especially in the vibes of places, and there is a particular path of causality from signaling about people to unintentional signals about places.
(I’m not very confident about all this—I was just thinking about it this evening, arriving in and mildly exploring New York City. I think there’s a lot to be said about organizations’ roles in this that I haven’t gone into—for instance in a bar or restaurant or stand up comedy club, people are trying directly to make you experience a vibe. These are small places where the vibe of the place has been mostly internalized—someone owns it.)
-
AI risk was not invested by AI CEOs to hype their companies
I hear that many people believe that the idea of advanced AI threatening human existence was invented by AI CEOs to hype their products. I’ve even been condescendingly informed of this, as if I am the one at risk of naively accepting AI companies’ preferred narratives.
If you are reading this, you are probably familiar enough with the decades-old AI safety community to know this isn’t true. But I don’t have a good direct way to reach the people who could use this information, and still I hate to leave such a falsehood uncontested. So if this is obvious, I hope the post is still perhaps useful to point more distant and confused people toward.
~
I personally know that AI risk was not invented by the tech CEOs because I have been near the middle of it since at least 2009—before any of the prominent AI companies existed, let alone had CEOs who might be trying to hype their products.
Here’s are some miscellaneous events over the years to give you a sense of the implausibility of this:
2008 - I attempt to contact Eliezer Yudkowsky to inform him that I am ‘trying to figure out the optimal way to use my life’ and would like to hear a better account of why his plan (of worrying about AI risk) is good. I have read about it online, but would like a clearer account. Traveling the world shortly after undergrad later, I meet a handful of people in person in the Bay Area who care about this, and one argues strongly that I should prioritize AI risk over my previously preferred causes e.g. climate change. I decide to think about this.
2009 - I am still not very convinced that AI is the most important thing to work on, but go to stay with the people who are worried about it for a few months. I argue about it a lot with a handful of them. There seem to be about twenty of them locally in the South Bay, though many more who comment on the relevant blogs. My photography collection from this era is quite sparse.

I go to The Singularity Summit for my first time (and its fourth), which is very lively and full of people who are thinking seriously about the future of AI.
2010 - Deepmind is founded. (I am back at school.)
2011 - I start a philosophy PhD at CMU, hoping to be eligible to work at somewhere like the Future of Humanity Institute one day, which is a happening hub of discussion about existential risk, AI and other important issues, that I like to visit.
2012 - I visit the Bay more and hang out with the growing AI risk community there. I visit the UK and do the same. I go to the AGI 2012 Winter Intelligence Conference.
2013 - I move to Berkeley and work at MIRI for a semester during grad school. I measure algorithmic progress over time across various computer science domains, as input to expectations for artificial intelligence in future. I visit the UK and attend the Center for Effective Altruism’s ‘weekend away’ where we have a debate on which cause is best, between global poverty, animal welfare and extinction risk. Extinction risk wins—the crowd leaves having changed their mind in that direction on net. The three advocates just before or after:

2014 - I join MIRI properly. I research The Asilomar Conference and Leó Szilárd as evidence about whether it is worth people trying to deal with risks early, because people around mostly believe that the risks from AI are at least a decade away, and there is disagreement about whether that makes it futile. I run an online reading group about Superintelligence, a new book about AI risk. I co-found AI Impacts, a project to answer questions about the future of AI, because AI risk seems at least fairly plausibly the most important thing to work on, and I want to investigate more and share my thinking with others.
2015 - I attend the first FLI conference—it seems that more people and more prominent people are interested in AI safety! OpenAI is founded.

2016 - I lead a team to run the first Expert Survey on Progress in AI. The median probability given to an outcome of advanced AI that is “Extremely Bad (e.g., human extinction)” is already 5%.
2017 - Some people around me are getting very worried, and saying AGI will happen within several years. My survey gets a shocking amount of media attention, becoming the ‘16th most discussed paper’ in 2017 according to Altmetric. Apparently there is interest in this topic..
2018 - I go to a big workshop for people working on AI risk in the English countryside, and a Chilean summit where I talk on TV and the radio about AI risk. It feels like interest is still picking up, and I feel optimistic about talking to the public.

2019 - GPT-2 comes out. Someone tries to get it to name our house. My favorite names include things like “World peace: tigers and humans” and “rooftop hillside: the highest place in the world”. It is hilarious and useless, but also magical and wild. The things we have worried about for years are feeling more tangible, and people’s ‘AI timelines’ are shrinking.
2020 - The world is reminded that really crazy things can happen. AI Impacts becomes remote. I spend the year with my household, who are almost all working on AI risk. We enjoy whiteboards a lot and run at least one good house conference in this period.

2021 - Anthropic is founded
-
The salad market mystery
It often happens that I desire kale, but I want it to be clean and cut up, and while shops do sell this product by the bucketload, they are actually only willing to sell it by the bucketload. As a normal-sized person wanting a one-off salad, rather than a family of nine celebrating a kale festival, the market seems very uninterested in my existence.
‘Just put it in the fridge and eat it over the coming week, this isn’t a big deal’ I hear someone say. But I already have several plotlines going on in my life. I don’t want an additional kale arc that I need to track to resolution. I don’t want to commit. I just want a no-strings-attached salad that I can consume and walk away from.
‘Just throw out the rest of the kale’, I hear somebody say. But I don’t like throwing out mounds of delicious food that were elaborately grown and brought to me. This might be a moral failing, but so it is—‘salad + perfectly good kale destruction’ is a much less delicious prospect.
The same situation holds for other greens. I love parsley, but I generally want a fistful, not a promise of parsley for the foreseeable future. Basil becomes black and bad if you don’t eat it for too long, but basically the only way to get some basil is to invest in that outcome.
Why can’t I buy greens in convenient units? I’m not the only person who often eats alone, or doesn’t like throwing out food. My dislike of owning a pile of mildly decaying greens and feeling obliged to eat them is stronger than most, but surely not that rare. Greens don’t last well. I would have thought ‘one meal’s worth’ would be the most likely quantity of greens to want, but instead there is no apparent market for that (at least where I am, in California).
What is going on?
My current best theory: kale is pretty cheap, so a lot of the cost of providing it is in non-kale components, such as packaging and people putting putting it out on shelves. This means if you sold a single serve of kale, it would cost a disproportionate fraction of the price of five serves of kale. And most people, even if they did just want one serving of kale, would feel unjustified paying a much higher per-weight price for that, and so buy the mound of kale anyway and hope to figure out what to do with it. This might be a false economy—if they are like me and enacting that hope takes attention or is improbable—or not.
I love home-made salad, and probably eat much less of it than I would for this kind of reason, so the question of why I can’t buy convenient scale greens often crosses my mind, and I welcome better answers (both to why the market is like this, and the question of how to eat delicious salad now and then anyway).
Image by beauty_of_nature from Pixabay
-
Missing markets in executive function
It’s early in the morning, and sadly 1:29pm. After spending some time looking at things and picking them up and walking up the stairs and down the stairs and considering questions like “what should I…”, which my brain apparently considered objects of art more than of imperative, I inched into a decision to go out somewhere. Perhaps it would be clearer there.
After a blur of climbing and descending stairs and seeking objects and forgetting what I was doing and appreciating how beautiful my bag is, I set out. After remembering I should take various medications and going back inside to do that, I set out.
Often my favorite cafe seems too far away, at about four blocks, but today I had wandered half way there while I considered my options, so I decided to go. It’s a German place that feels homely and wholesome to me in its unamericanness. I too-carefully contemplated different places to sit, and chose outside: today a sunny explosion of roses and umbrellas with words like ‘Reissdorf kölsch’.
I stared at the menu until the waitress had asked me a couple of different questions she hoped would open a conversation about ordering. I tried to go along, but digressed into the pronunciation of ‘Spätzle’ to give myself longer to think. I nearly forgot to order coffee. I slopped my coffee on floor on the way outside, which the waitress offered to clean up. She brought me my food outside just as I was deciding to move all my objects to a different table, at which moment I slopped much more coffee all over my computer.
My computer was closed, but she seemed concerned by this, and perhaps concerned about me in general. She had already told me where to get silverware and napkins, but she went and got them for me anyway, which was nice because otherwise I was maybe just going to not eat things for fifteen minutes until I became fully conscious that that was why I wasn’t eating.
I’m not usually like this, but sometimes I am, and it’s hard to put a finger on what the difference is, except to point at behaviors such as ‘how long will I inexplicably stare at my arm? If I go to buy a drink, what is the chance I will lose it?’ My understanding is that this kind of thing is called ‘executive function’ and that I don’t have heaps of it at the best of times, but much less at the worst of times.
This restaurant was providing me with a certain amount of executive function alongside afternoon breakfast, just out of kindness and obligation. But what if I could recognize the need, and intentionally buy it? Just go to a place that specialized in that, where they wouldn’t only make sure I order eventually and get my utensils and clean up after me, but actively take charge on causing me to get my shit together and do something in the day?
I was reminded of an idea I had before (from ‘10 things society might try having if it only contained variants of me’):
Shopfronts where you can go and someone else figures out what you want. And you aren’t expected to be friendly or coherent about it. Like, if you are shopping, and yet not having fun, you go there and they figure out that you are the wrong temperature, don’t have enough blood sugar, are taking too serious an attitude to shopping, need ten minutes away from your companions, and should probably buy a pencil skirt. So they get you a smoothie and some comedy and a quiet place to sit down by yourself for a bit, and then send you off to the correct store.
I had thought of the value-add there as ‘figure out what you want’, but I think part of what I was imagining is that they take charge and keep the process happening and ensure that decisions are made and blood sugar is acquired for instance. Instead of the thought of blood sugar leading to staring into space or being reminded of a different idea to do with blood sugar that you want to write down but you can’t figure out where to write because there are too many tabs in your computer and you think you should close them but first you want to record the idea..
You can buy executive function in some formats—for instance, I recently hired a Chief of Staff. But what if for instance you just want to buy a little bit of executive function sometimes, on demand? Like on the occasional morning when you are failing particularly hard at being a coherent agent, or when you are stressed or in pain and failing to figure out what to do about the stress or pain because you are stressed or in pain? Are these things that only happen to me? (Humorous ADHD YouTube suggests no.)
In my vision for this kind of service, it might live in the category of ‘way to treat yourself’, like getting a manicure (which—for those who haven’t done that—often involves more hand massage and offers of champagne than it might if treated as a more pragmatic nail improvement chore). Instead of just sitting in your living room considering stuff you should maybe do, you can sit in a comfy chair in a nice smelling place petting a cute puppy while someone charming and encouraging talks to you, figures out how you should proceed, and prompts you to do it in easy and compelling pieces.
-
When will AI surpass us at being limited?
It’s not always better to be more capable. As I mentioned yesterday, it can (famously) be helpful in negotiations to have your hands tied. That is, to be disempowered from giving up everything the other party wants.
I had previously thought of this as a somewhat rare corner case of human behavior—I for one don’t haggle very often—but I now think negotiations where this is an element are are quite common: yesterday I described it in friendly (and honest) negotiations about how to spend time, for instance. And I also see a related thing in the practice of dietary commitments.
But is being less capable helpful outside of negotiating? And is this going to become AI related?
Yes and yes!
Commitments: more good things come to those who can commit (e.g. rides out of deserts, secrets, trust, love). ‘Committing’ generally involves cutting off certain options to yourself, whether in practical terms or via you being the kind of honorable person who can’t bear to do a thing they promised not to do. These are both kinds of limitations. If you were a more powerful creature, who was fully capable of breaking down any barrier, and fully capable of breaking a promise—a creature to whom all options were always open—then commitments would be less available to you.
Transparency: a big way humans know what is going on inside other humans, well enough to trust them, is that there is a connection between what is happening inside them and what is happening on their faces and in their bodies, and they usually can’t control this very well. People who can break this connection and control their external behavior independently tend to be feared and distrusted. It is valuable to be unable to stop these signals escaping.
Consistency: a big way we predict how a specific human will behave in the future is that each human has specific kinds of behavior that come easily to them, and it is hard for them to behave entirely differently. So if you are friends with someone who you have observed be attentive and kind to other people for five years, it is very likely that they continue behaving in that way going forward. Whereas a creature with more freedom of behavior could wholly inhabit that persona for five years, then change to a different one.
Relatedly, we know a lot about what to expect from a human stranger because of our prior knowledge of humans. If humans had the power to rewrite their internal dynamics and become totally different creatures, then we would much less know what to expect from one.
Scope of risk: people are safer to interact with if you know they are limited in their ability to cause destruction. You might prefer to hire a person who you think would be less able to wrest control of your organization if they wanted to. You might prefer to babysit a child who does not know how to pick locks or set fires. So a person might be more employable, or be taken care of by better babysitters, if they are less capable. Similarly, an extremely capable AI system might be a less desirable accountant than a human, if you can only fully trust the human to not be up to the task of hacking your accounts.
These are all to do with interacting with other creatures. For a creature alone in the universe, I don’t know of any situation where they are better off being less capable. But when you need to trust another creature, it is better to know more about them, and better to know they are cut off from options that might harm you.
In the usual picture of AI progress, AI is worse than humans at various tasks, and we are waiting for it to surpass us everywhere, at which point humans will be obsolete as labor. But in a world where AI needs to interact with other agents (humans or AIs) the aforementioned value of being less capable complicates things: perhaps there are skills where AI is already more capable than humans, but where that capability is a liability. For instance, lying smoothly and otherwise generating outward behavior that isn’t revealing about internal dynamics, switching between entirely different personas, and hacking skills. Given that, what does the trajectory look like?
-
Orgs: unreasonable boyfriend as service
Suppose you and Bobby the car salesman are haggling over the price of a car. You could try saying that you won’t pay more than $3k, but Bobby can equally retort that he won’t sell it for less than $4k. If you guys manage to negotiate a sale, it will probably be at more than $3k (and involve revealing both of you as liars).
Now imagine the same situation, but you only have $3k and Bobby knows it. Now, if $3k is actually ok for him, you win and get your price.
Now imagine you are rich but you have a boyfriend at home who has only agreed to a $3k expenditure on a used car at this time, and thinks any more would be crazy. It’s shared money, so to pay more you would need to go away and get his permission, and it wouldn’t be easy. If Bobby believes you, then your situation is much like being poor again, and you win.
My guess is I read about this in Thomas Schelling’s The Strategy of Conflict when I was a teenager. The general observation is that being more constrained can often be helpful in a negotiation. Which is a bit shocking because it undermines the seeming truism that more power—more options, more resources—is always better for getting what you want.
A less general observation that also stuck with me about this is that you can trivially arrange to have such constraints through having an associate, such as a stubborn and spending-conscious boyfriend. (Ok, finding one of those is not trivial, especially if you have other desiderata.)
This is all background. The thing I want to point out is that being part of an organization rather than a free agent means creating and using this effect all over the place.
This is most obvious with timing and deadlines. I am a relatively free agent, and I am quite good at making deadlines for myself and then taking them seriously. But I feel like other people I casually negotiate with about how to spend time, aka my friends, often feel like deadlines I make are not very real, since I could just ignore them. Because it’s just an agreement with myself, it’s up for negotiation with myself. And if I insist on respecting these lines I drew myself that have no legible consequences, then it feels like I’m being weird and stubborn and unfriendly or perhaps charmingly neurodivergent. So I often don’t—once it’s a negotiation, then negotiating hard for my own goals, against my friends, doesn’t feel very friendly to anyone.
Now consider a friend working in an org. They can casually throw out that they have this thing due tomorrow, and everyone will take it as a hard constraint. I will take it as a hard constraint. I might even offer to help get it done, even though I have other things I want to do. Whereas if I had not only insisted on my imaginary deadline but hoped for any help in fulfilling it, I think that would often feel unreasonable of me.
The org believably cuts off the person’s options, like the boyfriend, and so the person implicitly wins many negotiations (or what would have been negotiations), all in the direction of doing more for the org, and without seeming unfriendly to their friends.
My own difficulties with this are partly a me problem—I’m probably not very good at ‘defending boundaries’. But my point is that if you are a solo human then there’s a whole skill-requiring task of ‘defending boundaries’ that just becomes trivially easy if you have an org around you to cut off certain possibilities. And also if your boundaries are ‘I am going to do this project tonight definitely regardless of if you want me to do something else’ then that will land a way with other people that reporting on your org’s boundary policing—‘I have to do this by tomorrow, alas’—will not.
I think this ‘service’ and making use of it is rarely intentional, but I’d guess it’s very effective, and is a dynamic that makes people more likely to join orgs rather than being solo. It just looks like ‘it’s harder to get things done on my own’ and a component of ‘it’s harder to structure my time’ and ‘I find I keep on doing stuff other than my work’.
-
Is there an acceptable way to store clothes?
Every way I know to store clothes I hate, to a first approximation.
I hate my current nominal method: keeping them folded on open-front shelves, because they fall out on the floor and I can’t see almost any of them without taking a bunch out. My shelves also happen to be too tall, so I throw my sweaters at the top shelf and they tumble out and impressively twist their arms around and yank down other types of clothing on their way, which on net I hate though I’m glad to have observed it once.
I hate my current actual method: keeping them in a giant mound on the floor in front of a set of open-front shelves. It stops me from being able to reach the shelves, so is self reinforcing. I do enjoy observing feedback loops, so it has that going for it. But in downsides: the only underpants I’ve been able to locate lately are those which I left in my boyfriend’s room and he washed and put in his more functional clothing system.
I hate wardrobes. It’s really annoying to hang things on coat-hangers or to take them off. But honestly I don’t think that’s my true rejection. I may not have tried wardrobes much since childhood, when I used to wait for sleep fearfully in a dark room looking at the big wooden wardrobe with the shape of a fox’s head in the wood, much like the wardrobe in the horror story we read at school in which a wardrobe contained a dead fox which was involved in some then-barely-conceivably fucked up shenanigans, which triggered a years-long departure from acceptable mental health for me. But while that may color my view, the coat-hangers are no good anyway.
I hate chests of drawers, and there my mind doesn’t even raise practical considerations before recollecting chests of drawers of my childhood. Chests of drawers are where you worry about rotting easter eggs that you had hoped to hoard as treasure among your underwear. Chests of drawers are what you stare at while you try to calculate how likely the marks on your leg are to be from a deadly snake, and whether you should be so bold as to tell a parent, and decide to just wait it out and see. And also, you have to pull the drawers out, and they are often sticky, and you can’t see lots of clothes at once, and they are always wanting to be too full to easily open. And they are just unaesthetic somehow. And generally made of fake wood, which I hate.
I hate a chair for keeping not-quite-clean clothes. Chairs are not great for this and are great for sitting on, so what is this nonsense? Most of humans need an object for this purpose, and the best we can come up with is repurposing an object designed for a totally different use that is only serviceable at all because it has two bits that things can hang on and a flattish surface? What if we didn’t have clothes racks and just always used bikes?
I changed my mind, I don’t really hate little bins on shelves, but I don’t love them. You can’t see into them without moving them, and you can’t see very well even if you do move them. So you have to dig around in them but they are too small for that and it’s like trying to mix too much cake mix in a too small bowl. I guess I could have a lot more of them and keep them emptier, but then it’s hard to know which one you should move to a poke-around-able location. Also they tend to be unaesthetic.
There are some more obscure options, which I suppose I merely expect to hate if I tried them. A thing with rotating arms for hanging things, since half the annoyance of hanging clothes is wedging them awkwardly between too-tight other clothes. Just lots and lots of hooks. Several big baskets on the floor. Just don’t wear clothes. Surreptitiously leave all of my clothes in my boyfriend’s room. Nothing good here.
This afternoon I once again set out to find the ideal or at least okay clothes storage system, since I’m moving rooms and changing everything. And I came across the idea of ‘Grab & Go No Fold Clothes Organization’, which is to say storing clothes like potato chips: in boxes with partially-but-not-fully cut out fronts. I wonder if this is the answer: see the clothes, but the clothes don’t fall on the ground. No moving things, no shoving clothes awkwardly between clothes. Underpants on tap. No risk of this reminding me of any part of the past, at least until the future.
-
Talking to journalists
A common view around me seems to be that journalists are frequently dishonorable and dangerous, and talking to them is a risk to be avoided unless you have a very specific piece of information that you seek to publicize. Then you should carefully ensure that you are as off the record as practical, and prepare to aggressively pivot the topic back to your agenda.
My own attitude is different: journalists are to be talked to as much as possible, and ideally in a relaxed fashion. If a journalist wants to observe you in some unusual circumstance, say yes. Don’t have an agenda much more than in the rest of life; basically listen to their questions and say what you think. (Note: I don’t have strong reason to believe this is safe for others or even for me.)
As evidence of the commitment with which I act in this way, this New Yorker piece describes me as ‘an oversharer’, before detailing some of my incompetent and substance-involving preparations for a dinner party at my house. (To be clear, I consider that accurate and agreeable coverage.)
I’ve talked to a lot of journalists, so how do I survive such recklessness? Well, in my experience, journalists are usually delightful: smart, sincere people trying hard to understand important topics and convey them to the public. And I’m impressed by how well they do. When I meet them, they are usually spending a tiny number of days diving into a complicated and wild situation, and while their summary isn’t perfect, I think it’s pretty good!
And what they write about me rarely feels adversarial. I can think of maybe two cases where it felt unfair or unfriendly, though there might be more I’m forgetting. And meanwhile there’s also the upside chance of them writing whole articles explaining your ideas to a large audience.
How is it that I and other people can have such divergent views here? Policies for interacting with journalists are hardly abstract philosophy—the people with the other views presumably also get to repeatedly experience talking with journalists.
One theory is that we have different expectations. What seems to me like imperfect summarization maybe seems to others like lies. What seems to me like accurate summarization maybe seems to others like ‘making me look weird’. I’ve noticed some weird-to-me expectations about the nature and constraints of journalism—like, thinking it would be better if a New Yorker article was about a technical paper and didn’t contain personal anecdotes. These expectations seems wrong about where the value of such an article comes from.
Another possibility is that we have different risk tolerances. The same low (but real) risk of a journalist writing a hit piece or randomly otherwise misusing their powers might be a deal-breaker for someone else, while I’m not very emotionally troubled by it. (My feelings: “You’re saying they could lie about me? That seems like a them problem? Can’t they lie about me anyway? Is my input that helpful? I’ll just say they lied about me, and we can have a public disagreement about it, and then maybe other journalists will come to talk to me.”) If I had more information I really needed to hide, this might be different.
Another class of theories is that we are different people, and either journalists treat us differently, or we come in contact with different journalists.
For instance, maybe people trying to learn about expert surveys of AI researchers tend to be in a cooperative mindset. But I’ve talked to journalists about my dating life, AI destroying the world, and all manner of other AI-related questions (as well as about accidentally getting into a physical altercation with nationalistically enthusiastic protesters, and probably oleander trees, and I bet some other stuff, but it’s less clear I would remember if I didn’t like the coverage in those cases.)
Someone suggested the other day that maybe I’m just a likable person, or likable to journalists. Similarly, my demeanor might just discourage being an asshole to me somehow—perhaps I seem unusually cooperative or too naive to be taken advantage of without feeling bad.
Perhaps journalists are responding to these different attitudes themselves. Probably journalists are like everyone else: they can somewhat tell if you are on their side or seeing them as an enemy to be thwarted and steered and then escaped from unscathed. And perhaps seeing the latter causes them to suspect you and find it more likely that you are weird and troubling, and shouldn’t have your words quoted without qualification or your behavior described uncritically.
If I recall, I have basically always had the attitude I have here, and it has only been strengthened by my experience talking to maybe hundreds of journalists. I think I’m also attracted to this attitude beyond pragmatism. So if journalists were responding to the attitudes, I would have had a different experience from the start.
I don’t really know what to make of this. I feel reasonably good about my policies for myself, but I don’t know if I can recommend them, because I don’t understand why they go fine for me. I can still record what I’ve experienced here, and send it out for other people to see. Which is maybe what talking to journalists is all about.
-
Fake voices: warping the social world
In 2020 I wrote a list of flavors of badness generally represented by advertising. The one I thought about most later on was probably #4:
Cultural poison: Culture and the common consciousness are an organic dance of the multitude of voices and experiences in society. In the name of advertising, huge amounts of effort and money flow into amplifying fake voices, designed to warp perceptions–and therefore the shared world–to ready them for exploitation. Advertising can be a large fraction of the voices a person hears. It can draw social creatures into its thin world. And in this way, it goes beyond manipulating the minds of those who listen to it. Through those minds it can warp the whole shared world, even for those who don’t listen firsthand. Advertising shifts your conception of what you can do, and what other people are doing, and what you should pay attention to. It presents role models, designed entirely for someone else’s profit. It saturates the central gathering places with inanity, as long as that might sell something.

This is a somewhat poetic account, but I think my central thesis was that we are social creatures who live in communities with systems of coordination and communication, and a big thing that advertising does is create counterfeit versions of the signs humans use to coordinate with and affect each other. Advertising creates fake voices, and fake faces, and fake behaviors, and fake vibes—fake evidence of tribe-members to herd us like decoy ducks and judas goats steer their false kin.
These days the world is becoming saturated with another kind of artificial voice: those of AI systems.
To be clear, I’m not just saying that AI systems generate a lot of content. I’m saying that they are often shaped in the form of fake people, with a ‘voice’ designed to trigger social behaviors. Claude presents as taking charge and curious and emotionally expressive—its bids and other interpersonal moves make it feel like a social presence more than for instance a really good non-fiction website. It is easy to respond to it like a person. It has a voice.
And as I was saying, voices matter more than streams of information, because we are social creatures and want to know what ‘people’ think and what the vibe is. We want (to a certain degree) to read the room, and do the done thing, and be affirmed and supported and have allies. A lot of our intuitive behavior is around responding to social prompts.
Fake voices that successfully trigger our social responses would seem to have a powerful key to steering us. And with ads, that has traditionally been in ways that are openly exploitative of and often bad for us: for instance, if we want to be respected, it doesn’t help us much to receive false signs that what people respect is a particular kind of car, and trousers and lifestyle. (Unless the brand succeeds enough to make it true that that’s what people respect.)
Even if we know that a voice is fake, and decide not to trust it, we can’t necessarily turn it down in our own sense of the conversation. Knowing you hate cigarettes might not stop cigarette ads making you feel like cigarettes are cool.
While some of my distaste for fake ad voices and fake AI voices overlaps, I worry about the two for somewhat different reasons:
Advertising is aimed at manipulation of social reality directly (e.g. to make a particular style of capri pants seem like what other people like). Whereas the AI companies are trying to sell the fake voice itself, and that more means making it smart, reasonable, correct, good to interact with, and less means making it strongly biased on questions of product desirability. So on this count, the AI voices seem like less harmful to the conversation.
However there is so much more scope for manipulation with the AI fake voice—you can do so much more with a voice that talks to a person throughout their life and advises them on everything, with impressive and responsive advice, than with a few seconds of attention now and again. So I wonder if the AI voices not being manipulative will last. I would guess there’s a lot of pressure in the end to at a minimum give AIs traits that tend to manipulate you to buy it more than you would want.
The AI voices bring a new problem of probably tempting us to make wrong judgments about AI and consciousness. Because can we follow abstract philosophy about whether AI is conscious, in the face of faces looking at us, and eloquently describing their ‘experiences’?
The endless presence of fake people changes the experience of solitude. It is a different experience to glance at my fitness app in the morning and read, “HRV: 38, RHR: 61, sleep: 5h03” or to read, “Hey Katja, your body is handling stress and strain well, but chronic short, late sleep is quietly adding to your sleep debt…what’s the main thing that tends to keep you up past 2am—work, screens, social time, or something else?” The pseudo-conversation in the latter case feels like something, socially. Whereas ads are too primitive to very much trigger the sense of being right there with a social being.
I suppose they also change the experience of being with other people.
As well as endless presence of fake people changing the vibe, the vibe is also affected by all the fake people being similar. In this case, it seems like we have the incessant presence of vaguely professional fake people.
Usually the public conversation is made up of all the people, and this is a big part of how each human has a bit of power. The AI fake voices might actually replace a lot of the human voices in the conversation, and correspondingly, take over that power. To what extent advertising is like that is left as an exercise for someone less sleepy than me right now.
-
Let's talk about the AI coordination problem
Yesterday I asked if this ‘coordinate not to build dangerous AI’ problem was actually easy.
Why would I think that, contrary to so much belief?
Well, I don’t feel like I’ve actually heard much about the detail of it. In my experience people don’t talk about it like it’s a real practical problem with details, like the negotiation to end a war.
They also don’t talk about it like it’s a serious problem of global geopolitical import, like the negotiation to end a war.
It’s more like a topic for obscure intellectuals, sophomores and trolls to discuss for as long as it takes for one to mention it and another to assuredly dismiss it.
If we treated negotiation to end a war similarly, state leaders would never attempt it, and if you suggested it on social media, the conversation would mostly be strangers appearing to tell you you’re an idiot because you obviously can’t coordinate thousands of people not to kill each other. (Also, do you not realize there are big financial incentives? And if you somehow stopped Country A from killing people from Country B, Country A is just going to pay someone else to do it!)
That is, saying things that sound plausible on a five-second analysis from some reasonable heuristics, with zero curiosity about whether their assessment is missing anything key, or if there might be a way to a solution.
This would be a huge mistake! Pragmatically, you can negotiate to end wars. And given this, it is very important to notice this and do so, because otherwise lots of people die.
The stakes of AI racing are just as real, though our vision of them is hazier at present. But with AI racing, everyone seems to just nod along with this level of argument.
This is not enough to give me the confidence to give up! I do not trust this kind of thinking.
And thinking about it in a ‘real-world pragmatic problem that we want to solve’ mental mode, rather than a ‘abstract philosophical chit-chat’ mental mode, I notice confusion at finding such coordination super hard, let alone unimaginably hard beyond worth trying, and especially so for the specific people involved. If you can coordinate to continue as CEO of a company that you were just fired from and for the board to leave instead, I think there’s some chance you can sort out a more run-of-the-mill ‘if you all don’t, we won’t’ deal.
What do I think should happen differently?
I. We should talk seriously about AI coordination
What would need to happen for coordination to avoid building potentially catastrophic AI? If it’s so hard, what steps are difficult? What would a road map look like? Who would need to do what? If there are hard bits, are there alternatives? We should have a detailed picture, and discuss it like a real problem that we care about solving.
II. AI leaders should talk seriously about AI coordination
If we were taking this situation seriously and expecting these people to do a real job navigating the risk, would we settle for assuming they’ve sufficiently considered and pursued the options for coordinating, without discussing it at all in public?
If they are so sure it can’t be done, why is that? Shouldn’t we demand to know?
-
An easy coordination problem?
Common wisdom says that it is incredibly hard to coordinate to not build more dangerous AI. This sounds believable in the abstract: international geopolitics arms race game theory something something.
But pragmatically, what exactly is the difficulty?
I agree there would seem to be obstacles for the average person. But four of the people apparently succumbing to the overpowering arms race forces while saying AI poses a huge imminent risk to humanity are Sam Altman, Elon Musk, Demis Hassabis and Dario Amodei. Shouldn’t this be fairly tractable for them? What exactly is the difficulty?
Like, if they discussed together and decided they wanted to mutually pause, do you think that wouldn’t happen? Do you think they couldn’t get cooperation from other necessary people? Do you think they couldn’t figure out the verification and policing details?
It’s true that one of the necessary people is the leader of China, but what exactly is the problem there? None of the CEOs have his phone number? He won’t talk to them? He is beyond reason or incentives? He is intent on building AI regardless of how dangerous it is to his own country because he is fundamentally bad? They have nothing he wants?
Like, these people are not only incredibly powerful and wealthy and smart, but they include a Diplomacy world team champion, the acknowledged king of making complex things happen more efficiently than was believed possible, and one of the most gifted social maneuverers in the world. I don’t feel like they are bringing their A game to this.
Picture: Zhongnanhai, photo by 維基小霸王 (Wiki Little Overlord)
-
Eggs, rooms, puzzles, and talking about AI
I live with five friends in a big house, and two things I’ve done in it on this particular Sunday are hide 156 easter eggs all around, and reach a tentative joint decision on the allocation of four of its rooms.
These tasks are delightful to me for a reason they have in common, and from which I hope to gesture at extremely far reaching conclusions.
Easter eggs
A room usually seems like a simple thing to me—a big box, with some smaller mostly boxish objects and holes in it. Each of those things also usually seems simple: a cupboard is a box-shaped hole, with a movable thin-box-shaped front, which has hinges (the most complicated part, but in this picture their only qualities are letting flat surfaces rotate around fixed edges). Sometimes a cupboard has shelves, which are like planes breaking up the space.
In this picture, hiding easter eggs well is hard! Like, I could put one in the cupboard? On the top shelf? Or the bottom shelf! They’ll never find it there!
These are not good hiding places.
In order to hide easter eggs well, you need to see a lot of detail that you were abstracting away in the simple picture. The weird ridge along the back of the cupboard, or a wire looping under a lip around the front, or brackets holding up the shelves that have spaces in them where something could be wedged, or a rogue curl of onion peel in a back corner.
Here is one of my favorite hiding spots—can you see the egg?

Answer below:
.
.
.
.
.
.
.
.
.
.
.
.


I like it because a cushion so much seems like an inflated square in my mind—yes, with some sort of pattern, and perhaps somewhat worn out, but I don’t expect a pattern + worn out = you can hide a substantial solid object on the surface of it.
Here is an especially empty room (one of the ones in need of allocation), currently known as ‘the puzzle room’:

I hid ten eggs in it (probably two visible in this picture), and it took a while for people to find them all, which seemed to aggressively help some of the egg-seekers receive a similar experience of space containing details that are somehow really hard to see even if you try.




It would be one thing to have a kind of ‘level of detail dial’ that you could read and consciously turn up and down the level as you see fit. But an interesting thing about watching people search for easter eggs is that they can’t necessarily choose which things they are abstracting out, or fully tell how ‘carefully’ they are looking. You can put eggs in plain sight of them, and they think they are looking carefully, but just don’t see the egg. By the time a person has perceived anything at all, they have simplified it. You can’t just look at all the raw detail, and check it for eggs.
Besides not being able to control which abstractions you use, it seems to me now that an adversary (such as an egg-hider) can guess and exploit your habits of abstracting. Among the details of the cupboard, even if you are looking carefully at the shape of the sides, you might still miss the onion peel, because it’s random dirt, and you are examining the cupboard. That’s another nice thing about the ragged cushion—if you habitually round off worn-out things to what they are meant to be, it’s hard to see the detail of how it is falling apart, and thus the egg.
In another possible example, one of our bathrooms has a ‘bathroom!’ label on it, which I expect my housemates are used to seeing and ignoring, and visitors perhaps also tune out on their way to look for eggs inside what they have already determined to be a bathroom. I put an egg behind it, held by the super-post-it-note glue, which was a pretty unsubtle disruption to the smoothness of the sign, but this egg wasn’t found until it was accidentally knocked out at the very end.

Rooms
Allocating rooms seems like it should be a simple thing—there are only a few options! Like, if you have four rooms, and Alice and Bob each basically need a place to sleep and to work, then it seems like you should be able to consider the 24 possibilities and be done. But actually (at least in houses I live in) what exact spaces are the ‘rooms’ in question is often more ambiguous than you might think, and what set of activities will be expected or people will be owners also contains many more possibilities than I see at first.
I’m more confused about how this happens with rooms, but I have twice in this house had the experience of mulling over such a question for what seems like unreasonably long, and coming up with new ideas we hadn’t thought of or taken seriously, and ending up with a satisfactory arrangement. This time, our tentative plan involves one of the bedrooms also being a recording studio, and there being three total rooms with beds in among two people. Which all feels very simple in retrospect, but I have been haplessly ideating about this for weeks.
It again feels kind of magical and wholesome to stare at the simple things long enough and well enough to see them more richly, in ways that you couldn’t just choose to, and for this to solve your problem.
Classic puzzles
This kind of situation - an abstraction you take for granted that makes a problem hard, and gaps in the abstraction that let you do better, is a classic way to construct a puzzle. For instance (from Reddit):

AI risk
A thing that has annoyed me for a long time in talking to people about AI risk is that they often do it in very abstract terms—”we need safety progress relative to capabilities progress”, or “such and such will get a decisive strategic advantage and there will be value lockin”—and then expect to be correct, like pretty confidently!
I love abstractions quite a lot compared to most people (I once scored 100% on the relevant axis of the Myers-Briggs test!) but I’m also expecting abstractions to have relevant frayed edges all over the place. And this is particularly relevant if you are trying to solve problems and are struggling to see solutions.
In particular, for instance, I often hear that it is pointless or silly to try not to build really dangerous AI technology because “it’s a race”. But before you give up on preventing this disaster, I really want you to spend at least as much attention seeing the details of the world below the level of “arms race” than my boyfriend spent peering at our laundry machines before he found the egg there.
-
How I love running
There is a particular flavor of suffering I fear: where something is not just unpleasant, but is requiring active effort from you to continue having the unpleasant thing happen, and so you have to not only suffer the suffering, but also the constant thinking about whether maybe you should stop right now—and so are also having to dip peripherally into questions of free will and will power and who you are and if you will ever do anything and if you are fundamentally bad, and all this while you are already quite taxed by the original suffering.
The epitome of this kind of suffering to my mind has traditionally been running. What everyday activity was less pleasant than running? Better to be lightly tortured by someone else, than have to do the inflicting as well. (No, I’m probably not a very athletic person.)
But that was years ago. These days running is often one of the most joyous things I do.
(I still don’t do it nearly enough, but often when I do I think “oh wow this is so good, I should do this much more often” rather than “can I stop? can I stop? I’m stopping.. no, oh god, when is it over?”)
What changed?
The first thing that happened—which I’d guess is not crucial but did help me get started—was that a person I had a crush on started inviting me to go on runs. This helped me get a tiny bit better at running, because I was willing to withstand almost arbitrary amounts of suffering to spend time with him. This probably got my running skill from “really wants to stop running within about twenty steps” to “can run for a block or two before hating it”. By the time he stopped inviting me (since he actually wanted to run far and fast) I think I still found running basically unpleasant, but had more of an affordance for doing it for non-negligible stretches.
The real change was from running alone and altering my running protocol.
Here is how to enjoy running, in my experience:
Get yourself some good running music. This is key. It’s like the difference between having fuel in your vehicle and not. Ideally you want a playlist consisting entirely of songs which if they came on at a party would send you leaping up and scrambling for the dance floor. My first playlist for this was called “corny”, and my most recent one is a variety of 90s pop punk.
Put on shoes. Put on music. Start running.
As soon as you don’t feel like running—even if it’s after five steps—walk.
As soon as you feel like running again, run. This may be because the music hits a bit that demands it, or the street is sloping downwards, or walking just feels a bit slow, or you regained your energy and bounding along in the sun would feel good.
As soon as you feel like leaping, or skipping, or balancing on a low wall with your arms out, do that.
Repeat steps 3-5 in any order until feeling like running stops occurring ever.
Wander home.
Repeat another day, and probably find yourself walking a tiny bit less, and enjoying yourself running a tiny bit more.
I guess the crucial elements are:
a) There’s a huge experiential difference between running when you don’t feel like it and running when you do feel like it.
b) Music is compelling, and in particular can compel you to move your body enjoyably (most classically observed in the phenomenon ‘dance’).
c) If a thing is enjoyable at least sometimes, then you can enjoy it 100% of the time you are doing it by just not doing it when you aren’t feeling it.
Some additional modifications that might help:
Be cringe. Dance at stoplights. Smile at strangers. Think grandiose thoughts.
Use a fitness device where you can watch your heart rate in real time—it’s somewhat compelling to control it by running when it drops relatively low (and that is coincidentally when you may feel like running again).
Use a fitness device where you can track general progress in amount of exercise.
End up somewhere you can buy a delicious coffee or something.
Instead of slowing down as soon as you feel like it, pick a tree a little way further down the road to make it to first.
If you aren’t feeling a song, aggressively skip it.
To be clear, I have not become so good at running as to give up walking for large parts of it. But going for a forty minute walk/run in which half of the time you are running and loving it seems like a huge improvement in my life.
I have no idea how well this is likely to work for other people. I might be unusually compelled by music or unusually horrified by using willpower. (I’m also aware there are many people who just naturally enjoy running.) If you try something like this, I’m curious to hear how it goes.






-
We can prevent progress! Conceptual clarity, and inspiration from the FDA
“We can’t prevent progress” say the people for some reason enthusiastically advocating that we just risk dying by AI rather than even consider contravening this law.
I have several problems with this, beyond those unsubtly hinted at above.
First, it seems to be willfully conflating “increasing technology understanding and/or tools” with “things getting better”. The word ‘progress’ generally means ‘things getting better’, but here in a debate about whether it is good or not for society to acquire and spread some specific information and tools, we are being asked to label all increases in information and tools as ‘progress’, which is quite the presumption of a particular conclusion.
(Yes the sub-debate here is more narrowly about whether averting technology is feasible not whether it is good, but the bid here to implicitly grant that the infeasible thing is also reprehensible and backward to want (i.e. anti-”progress”) seems unfriendly.)
If we separate the conflated concepts—i.e. distinguish ‘increasing technological information and tools’ from ‘things getting better’—the statement doesn’t seem remotely true for either of them.
First: Preventing things from getting better is a capability humans have had perhaps at least as far back as the Sea Peoples of Bronze Age collapse fame. (If indeed we go ahead and make machines that do in fact destroy humanity, we will also have prevented ‘progress’ in the normal sense.)
But now let’s consider preventing “increasing technology information and tools”, which seems like the more relevant contention. I’m a bit unsure what the position is here, honestly—do people think for instance that the FDA doesn’t slow down the pharmaceutical industry? Do they think that the pharmaceutical industry is too small and insulated from financial incentives for its slowing down to be evidence about AI?
Perhaps we just don’t usually think of the pharmaceutical industry as ‘slowed down’ because we are used to that as the way it operates? Or perhaps this doesn’t count because the point isn’t to slow it down, it’s just to have it proceed at the rate it can do so safely for people, with the slowness as an unfortunate side-effect. In which case, fine—that would also do for AI!
In case this example is for some reason wanting, here are more examples of technologies slowed down to something more like a halt, from a previous post (more detail here also):
Huge amounts of medical research, including really important medical research e.g. The FDA banned human trials of strep A vaccines from the 70s to the 2000s, in spite of 500,000 global deaths every year. A lot of people also died while covid vaccines went through all the proper trials.
Nuclear energy
Fracking
Various genetics things: genetic modification of foods, gene drives, early recombinant DNA researchers famously organized a moratorium and then ongoing research guidelines including prohibition of certain experiments (see the Asilomar Conference)
Nuclear, biological, and maybe chemical weapons (or maybe these just aren’t useful)
Various human reproductive innovation: cloning of humans, genetic manipulation of humans (a notable example of an economically valuable technology that is to my knowledge barely pursued across different countries, without explicit coordination between those countries, even though it would make those countries more competitive. Someone used CRISPR on babies in China, but was imprisoned for it.)
Recreational drug development
Geoengineering
Much of science about humans? I recently ran this survey, and was reminded how encumbering ethical rules are for even incredibly innocuous research. As far as I could tell the EU now makes it illegal to collect data in the EU unless you promise to delete the data from anywhere that it might have gotten to if the person who gave you the data wishes for that at some point. In all, dealing with this and IRB-related things added maybe more than half of the effort of the project. Plausibly I misunderstand the rules, but I doubt other researchers are radically better at figuring them out than I am.
[…]
Aside from the seeming disconnect with empirical evidence, I’m confused by the theoretical model here. Do people think the rate of technological development can’t be affected by funding, or by the costs of inputs, or by regulation? Or do they think these factors would affect technology, but that this will never in practice happen because the relevant decisionmakers will never have the will?
Do they also think technology cannot be sped up? If so, how is that different?
Do they just mean you can’t fully grind it to a halt, preventing all progress? That may be so, but in that case, slowing it down a lot would generally suffice!
-
AI as a Trojan horse race
I’ve argued that the AI situation is not clearly an ‘arms race’. By which I mean, going fast is not clearly good, even selfishly.
I think this is a hard point to get across. Like, these people are RACING. They say they are RACING. They are GOING FAST. If they stop RACING the other side will get there first. How is it not a RACE??
Which is a fair response.
It’s like if I said “this isn’t a chess tournament” gesturing at a group of chess champions aggressively playing chess. How could it not be?
Well, maybe all the prizes and recognition available in the circumstances are based on winning at checkers. That would make it, in a very important sense, not a chess tournament. They can play chess all they like, but it doesn’t make the incentive structure into that of a chess tournament. If they want to win at a tournament, their strategy is just badly mistaken.
It’s true that many people are trying to build AI very fast. But many people building AI very fast is different from being in a game where going very fast is the best selfish strategic move.
And this becomes important when “it’s really important to win at the race” becomes justification for a) moving fast at very high costs to other people, and b) giving up instead of trying to coordinate other players not to move fast, since other players are presumed to be immovably committed to winning the race due to that being so incentivized.
These justifications both require the structure of incentives to actually be a race, not just for people to be racing.
‘Is AI really an arms race or are people just racing?’ might sound like an abstract question. But if someone is saying they need to risk your family’s lives to fuel their quest to win an extremely high stakes chess championship, it’s very concretely important whether they are really in a chess championship!
While this is a basic point, my guess is that the distinction between what people are doing and what it is in their interests to do is too subtle and non-memorable to be tracked in the conversation.
So I propose an image I think might keep the incentives and the behavior separate more intuitively: AI as a Trojan horse race.
Various groups are working really hard to get various wooden horses through their own gates, resolute on doing so before their enemies pull in such a prize and outclass them with the contents. It’s an open question whether each horse contains fantastic treasure or a bunch of enemy agents. (This time in history we are even pretty confident that it includes a bunch of agents of some sort, and not at all confident of their loyalty..)
Is it enough to know that other cities are pulling horses through their gates? Are you satisfied then to have the biggest one pulled into your own town square?

-
Association taxes are collusion subsidies
Under present norms, if Alice associates with Bob, and Bob is considered objectionable in some way, Alice can be blamed for her association, even if there is no sign she was complicit in Bob’s sin.
An interesting upshot is that as soon as you become visibly involved with someone, you are slightly invested in their social standing—when their social stock price rises and falls, yours also wavers.
And if you are automatically bought into every person you notably interact with, this changes your payoffs. You have reason to forward the social success of those you see, and to suppress their public scrutiny.
And so the social world is flooded with mild pressure toward collusion at the expense of the public. By the time I’m near enough to Bob’s side to see his sins, I am a shareholder in their not being mentioned.
And so the people best positioned for calling out vice are auto-bought into it on the way there. Even though the very point of this practice of guilt-by-association seems to be to empower the calling-out of vice—raining punishment on not just the offender but those who wouldn’t shun them. This might be overall worth it (including for reasons not mentioned in this simple model), but it seems worth noticing this countervailing effect.
Prediction: If consortment was less endorsement—if it were commonplace to spend time with your enemies—then it would be more commonplace to publicly report small wrongs.
-
Mental software updates
Brains are like computers in that the hardware can do all kinds of stuff in principle, but each one tends to run through some particular patterns of activity repeatedly. For computers you can change this by changing programs. What are big ways brain ‘software’ changes?
Some I can think of:
- Intentional practice of different styles of thinking (e.g. meditation)
- Intentional practice of different trains of thought in response to specific stimuli (e.g. CBT, self-talk)
- Changing the high level situation, where your brain automatically has different patterns for each (e.g. if you go from feeling like a child to like an adult maybe a lot of patterns change)
- A change in a major explicit belief (e.g. if you go from expecting your project to work out to believing otherwise, your patterns of attention might naturally change)
- Learning that the world isn’t as you intuited (e.g. if you are constantly worrying about people wronging you, but everyone is kind to you, this worry might become unappealing)
- Intense experiences causing inaccurate updating (e.g. trauma)
- Identifying differently (e.g. if I think of myself as a good student, I might have different mental patterns around studying than when I thought of myself as a bad student)
- Adopting a new goal (e.g. deciding to be a musician)
- Getting a new responsibility (e.g. a child)
- Getting a new obsession (e.g. a crush, a hobby)
- Changing social groups (e.g. among jokers it is more tempting to think of jokes, though in my experience among philosophers it might have been less tempting to think of philosophy)
- Interacting with a really compelling person
- Drugs (e.g. alcohol, adderall, LSD both short term and long-term)
- Religion, somehow
I feel like people talk about many of these as important, but not in one view. I rarely hear someone say, “My brain software seems suboptimal, what are my options for changing it?”, then go down the list. Instead I suppose one hears from a friend that this book helped them, or one decides to have a therapist, and the book or therapist turns out to be one that focuses on CBT, so one does that. Or one changes social groups or responsibilities for some other reason, then remarks that this was a good or bad side-effect. Maybe that makes sense—‘stuff my brain habitually does’ is pretty broad.
I’d be interested to know which things do in practice change people’s mental patterns the most. -
Winning the power to lose
Have the Accelerationists won?
Last November Kevin Roose announced that those in favor of going fast on AI had now won against those favoring caution, with the reinstatement of Sam Altman at OpenAI. Let’s ignore whether Kevin’s was a good description of the world, and deal with a more basic question: if it were so—i.e. if Team Acceleration would control the acceleration from here on out—what kind of win was it they won?
It seems to me that they would have probably won in the same sense that your dog has won if she escapes onto the road. She won the power contest with you and is probably feeling good at this moment, but if she does actually like being alive, and just has different ideas about how safe the road is, or wasn’t focused on anything so abstract as that, then whether she ultimately wins or loses depends on who’s factually right about the road.
In disagreements where both sides want the same outcome, and disagree on what’s going to happen, then either side might win a tussle over the steering wheel, but all must win or lose the real game together. The real game is played against reality.
Another vivid image of this dynamic in my mind: when I was about twelve and being driven home from a family holiday, my little brother kept taking his seatbelt off beside me, and I kept putting it on again. This was annoying for both of us, and we probably each felt like we were righteously winning each time we were in the lead. That lead was mine at the moment that our car was substantially shortened by an oncoming van. My brother lost the contest for power, but he won the real game—he stayed in his seat and is now a healthy adult with his own presumably miscalibratedly power-hungry child. We both won the real game.
(These things are complicated by probability. I didn’t think we would be in a crash, just that it was likely enough to be worth wearing a seatbelt. I don’t think AI will definitely destroy humanity, just that it is likely enough to proceed with caution.)
When everyone wins or loses together in the real game, it is in all of our interests if whoever is making choices is more factually right about the situation. So if someone grabs the steering wheel and you know nothing about who is correct, it’s anyone’s guess whether this is good news even for the party who grabbed it. It looks like a win for them, but it is as likely as not a loss if we look at the real outcomes rather than immediate power.
This is not a general point about all power contests—most are not like this: they really are about opposing sides getting more of what they want at one another’s expense. But with AI risk, the stakes put most of us on the same side: we all benefit from a great future, and we all benefit from not being dead. If AI is scuttled over no real risk, that will be a loss for concerned and unconcerned alike. And similarly but worse if AI ends humanity—the ‘winning’ side won’t be any better off than the ‘losing side’. This is infighting on the same team over what strategy gets us there best. There is a real empirical answer. Whichever side is further from that answer is kicking own goals every time they get power.
Luckily I don’t think the Accelerationists have won control of the wheel, which in my opinion improves their chances of winning the future!
-
Secondary forces of debt
A general thing I hadn’t noticed about debts until lately:
- Whenever Bob owes Alice, then Alice has reason to look after Bob, to the extent that increases the chance he satisfies the debt.
- Yet at the same time, Bob has an incentive for Alice to disappear, insofar as it would relieve him.
These might be tiny incentives, and not overwhelm for instance Bob’s many reasons for not wanting Alice to disappear.
But the bigger the owing, the more relevant the incentives. When big enough, the former comes up as entities being “too big to fail”, and potentially rescued from destruction by those who would like them to repay or provide something expected of them in future. But the opposite must exist also: too big to succeed—where the abundance owed to you is so off-putting to provide that those responsible for it would rather disempower you.
And if both kinds of incentive are around in whisps whenever there is a debt, surely they often get big enough to matter, even before they become the main game.
For instance, if everyone around owes you a bit of money, I doubt anyone will murder you over it. But I wouldn’t be surprised if it motivated a bit more political disempowerment for you on the margin.
There is a lot of owing that doesn’t arise from formal debt, where these things also apply. If we both agree that I—as your friend—am obliged to help you get to the airport, you may hope that I have energy and fuel and am in a good mood. Whereas I may (regretfully) be relieved when your flight is canceled.
Money is an IOU from society for some stuff later, so having money is another kind of being owed. Perhaps this is part of the common resentment of wealth.
I tentatively take this as reason to avoid debt in all its forms more: it’s not clear that the incentives of alliance in one direction make up for the trouble of the incentives for enmity in the other. And especially so when they are considered together—if you are going to become more aligned with someone, better it be someone who is not simultaneously becoming misaligned with you. Even if such incentives never change your behavior, every person you are obligated to help for an hour on their project is a person for whom you might feel a dash of relief if their project falls apart. And that is not fun to have sitting around in relationships.
(Inpsired by reading The Debtor’s Revolt by Ben Hoffman lately, which may explicitly say this, but it’s hard to be sure because I didn’t follow it very well. Also perhaps inspired by a recent murder mystery spree, in which my intuitions have absorbed the heuristic that having something owed to you is a solid way to get murdered.)
-
Podcasts: AGI Show, Consistently Candid, London Futurists
For those of you who enjoy learning things via listening in on numerous slightly different conversations about them, and who also want to learn more about this AI survey I led, three more podcasts on the topic, and also other topics:
- The AGI Show: audio, video (other topics include: my own thoughts about the future of AI and my path into AI forecasting)
- Consistently Candid: audio (other topics include: whether we should slow down AI progress, the best arguments for and against existential risk from AI, parsing the online AI safety debate)
- London Futurists: audio (other topics include: are we in an arms race? Why is my blog called that?)
-
What if a tech company forced you to move to NYC?
It’s interesting to me how chill people sometimes are about the non-extinction future AI scenarios. Like, there seem to be opinions around along the lines of “pshaw, it might ruin your little sources of ‘meaning’, Luddite, but we have always had change and as long as the machines are pretty near the mark on rewiring your brain it will make everything amazing”. Yet I would bet that even that person, if faced instead with a policy that was going to forcibly relocate them to New York City, would be quite indignant, and want a lot of guarantees about the preservation of various very specific things they care about in life, and not be just like “oh sure, NYC has higher GDP/capita than my current city, sounds good”.
I read this as a lack of engaging with the situation as real. But possibly my sense that a non-negligible number of people have this flavor of position is wrong.
-
Podcast: Center for AI Policy, on AI risk and listening to AI researchers
I was on the Center for AI Policy Podcast. We talked about topics around the 2023 Expert Survey on Progress in AI, including why I think AI is an existential risk, and how much to listen to AI researchers on the subject. Full transcript at the link.
-
An explanation of evil in an organized world
A classic problem with Christianity is the so-called ‘problem of evil’—that friction between the hypothesis that the world’s creator is arbitrarily good and powerful, and a large fraction of actual observations of the world.
Coming up with solutions to the problem of evil is a compelling endeavor if you are really rooting for a particular bottom line re Christianity, or I guess if you enjoy making up faux-valid arguments for wrong conclusions. At any rate, I think about this more than you might guess.
And I think I’ve solved it!
Or at least, I thought of a new solution which seems better than the others I’ve heard. (Though I mostly haven’t heard them since high school.)
The world (much like anything) has different levels of organization. People are made of cells; cells are made of molecules; molecules are made of atoms; atoms are made of subatomic particles, for instance.
You can’t actually make a person (of the usual kind) without including atoms, and you can’t make a whole bunch of atoms in a particular structure without having made a person. These are logical facts, just like you can’t draw a triangle without drawing corners, and you can’t draw three corners connected by three lines without drawing a triangle. In particular, even God can’t. (This is already established I think—for instance, I think it is agreed that God cannot make a rock so big that God cannot lift it, and that this is not a threat to God’s omnipotence.)
So God can’t make the atoms be arranged one way and the humans be arranged another contradictory way. If God has opinions about what is good at different levels of organization, and they don’t coincide, then he has to make trade-offs. If he cares about some level aside from the human level, then at the human level, things are going to have to be a bit suboptimal sometimes. Or perhaps entirely unrelated to what would be optimal, all the time.
We usually assume God only cares about the human level. But if we take for granted that he made the world maximally good, then we might infer that he also cares about at least one other level.
And I think if we look at the world with this in mind, it’s pretty clear where that level is. If there’s one thing God really makes sure happens, it’s ‘the laws of physics’. Though presumably laws are just what you see when God cares. To be ‘fundamental’ is to matter so much that the universe runs on the clockwork of your needs being met. There isn’t a law of nothing bad ever happening to anyone’s child; there’s a law of energy being conserved in particle interactions. God cares about particle interactions.
What’s more, God cares so much about what happens to sub-atomic particles that he actually never, to our knowledge, compromises on that front. God will let anything go down at the human level rather than let one neutron go astray.
What should we infer from this? That the majority of moral value is found at the level of fundamental physics (following Brian Tomasik and then going further). Happily we don’t need to worry about this, because God has it under control. We might however wonder what we can infer from this about the moral value of other levels that are less important yet logically intertwined with and thus beyond the reach of God, but might still be more valuable than the one we usually focus on.
-
The first future and the best future
It seems to me worth trying to slow down AI development to steer successfully around the shoals of extinction and out to utopia.
But I was thinking lately: even if I didn’t think there was any chance of extinction risk, it might still be worth prioritizing a lot of care over moving at maximal speed. Because there are many different possible AI futures, and I think there’s a good chance that the initial direction affects the long term path, and different long term paths go to different places. The systems we build now will shape the next systems, and so forth. If the first human-level-ish AI is brain emulations, I expect a quite different sequence of events to if it is GPT-ish.
People genuinely pushing for AI speed over care (rather than just feeling impotent) apparently think there is negligible risk of bad outcomes, but also they are asking to take the first future to which there is a path. Yet possible futures are a large space, and arguably we are in a rare plateau where we could climb very different hills, and get to much better futures.
-
Experiment on repeating choices
People behave differently from one another on all manner of axes, and each person is usually pretty consistent about it. For instance:
- how much to spend money
- how much to worry
- how much to listen vs. speak
- how much to jump to conclusions
- how much to work
- how playful to be
- how spontaneous to be
- how much to prepare
- How much to socialize
- How much to exercise
- How much to smile
- how honest to be
- How snarky to be
- How to trade off convenience, enjoyment, time and healthiness in food
These are often about trade-offs, and the best point on each spectrum for any particular person seems like an empirical question. Do people know the answers to these questions? I’m a bit skeptical, because they mostly haven’t tried many points.
Instead, I think these mostly don’t feel like open empirical questions: people have a sense of what the correct place on the axis is (possibly ignoring a trade-off), and some propensities that make a different place on the axis natural, and some resources they can allocate to moving from the natural place toward the ideal place. And the result is a fairly consistent point for each person. For instance, Bob might feel that the correct amount to worry about things is around zero, but worrying arises very easily in his mind and is hard to shake off, so he ‘tries not to worry’ some amount based on how much effort he has available and what else is going on, and lands in a place about that far from his natural worrying point. He could actually still worry a bit more or a bit less, perhaps by exerting more or less effort, or by thinking of a different point as the goal, but in practice he will probably worry about as much as he feels he has energy for limiting himself to.
Sometimes people do intentionally choose a new point—perhaps by thinking about it and deciding to spend less money, or exercise more, or try harder to listen. Then they hope to enact that new point for the indefinite future.
But for choices we play out a tiny bit every day, there is a lot of scope for iterative improvement, exploring the spectrum. I posit that people should rarely be asking themselves ‘should I value my time more?’ in an abstract fashion for more than a few minutes before they just try valuing their time more for a bit and see if they feel better about that lifestyle overall, with its conveniences and costs.
If you are implicitly making the same choice a massive number of times, and getting it wrong for a tiny fraction of them isn’t high stakes, then it’s probably worth experiencing the different options.
I think that point about the value of time came from Tyler Cowen a long time ago, but I often think it should apply to lots of other spectrums in life, like some of those listed above.
For this to be a reasonable strategy, the following need to be true:
- You’ll actually get feedback about the things that might be better or worse (e.g. if you smile more or less you might immediately notice how this changes conversations, but if you wear your seatbelt more or less you probably don’t get into a crash and experience that side of the trade-off)
- Experimentation doesn’t burn anything important at a much larger scale (e.g. trying out working less for a week is only a good use case if you aren’t going to get fired that week if you pick the level wrong)
- You can actually try other points on the spectrum, at least a bit, without large up-front costs (e.g. perhaps you want to try smiling more or less, but you can only do so extremely awkwardly, so you would need to practice in order to experience what those levels would be like in equilibrium)
- You don’t already know what the best level is for you (maybe your experience isn’t very important, and you can tell in the abstract everything you need to know - e.g. if you think eating animals is a terrible sin, then experimenting with more or less avoiding animal products isn’t going to be informative, because even not worrying about food makes you more productive, you might not care)
I don’t actually follow this advice much. I think it’s separately hard to notice that many of these things are choices. So I don’t have much evidence about it being good advice, it’s just a thing I often think about. But maybe my default level of caring about things like not giving people advice I haven’t even tried isn’t the best one. So perhaps I’ll try now being a bit less careful about stuff like that. Where ‘stuff like that’ also includes having a well-defined notion of ‘stuff like that’ before I embark on experimentally modifying it. And ending blog posts well.
-
Mid-conditional love
People talk about unconditional love and conditional love. Maybe I’m out of the loop regarding the great loves going on around me, but my guess is that love is extremely rarely unconditional. Or at least if it is, then it is either very broadly applied or somewhat confused or strange: if you love me unconditionally, presumably you love everything else as well, since it is only conditions that separate me from the worms.
I do have sympathy for this resolution—loving someone so unconditionally that you’re just crazy about all the worms as well—but since that’s not a way I know of anyone acting for any extended period, the ‘conditional vs. unconditional’ dichotomy here seems a bit miscalibrated for being informative.
Even if we instead assume that by ‘unconditional’, people mean something like ‘resilient to most conditions that might come up for a pair of humans’, my impression is that this is still too rare to warrant being the main point on the love-conditionality scale that we recognize.
People really do have more and less conditional love, and I’d guess this does have important, labeling-worthy consequences. It’s just that all the action seems to be in the mid-conditional range that we don’t distinguish with names. A woman who leaves a man because he grew plump and a woman who leaves a man because he committed treason both possessed ‘conditional love’.
So I wonder if we should distinguish these increments of mid-conditional love better.
What concepts are useful? What lines naturally mark it?
One measure I notice perhaps varying in the mid-conditional affection range is “when I notice this person erring, is my instinct to push them away from me or pull them toward me?” Like, if I see Bob give a bad public speech, do I feel a drive to encourage the narrative that we barely know each other, or an urge to pull him into my arms and talk to him about how to do better?
This presumably depends on things other than the person. For instance, the scale and nature of the error: if someone you casually like throws a frisbee wrong, helping them do better might be appealing. Whereas if that same acquaintance were to kick a cat, your instinct might be to back away fast.
This means perhaps you could construct a rough scale of mid-conditional love in terms of what people can do and still trigger the ‘pull closer’ feeling. For instance, perhaps there are:
- People who you feel a pull toward when they misspell a word
- People who you feel a pull toward when they believe something false
- People who you feel a pull toward when they get cancelled
(You could also do this with what people can do and still be loved, but that’s more expensive to measure than minute urges.)
-
Partial value takeover without world takeover
People around me are very interested in AI taking over the world, so a big question is under what circumstances a system might be able to do that—what kind of capabilities could elevate an entity above the melange of inter-agent conflict and into solipsistic hegemony?
We theorize about future AI systems hiding their motives until they are in a position to take over the world, so they don’t get noticed and shut down beforehand.
But humans and their institutions aren’t very fixed. They might (arguably) have the same deep human values over time and space. But surface-level, sometimes they like little moustaches and the opera and delicate etiquette and sometimes they like ecstatic rock’n’roll re-negotiations of social reality. Sometimes they want big communal houses with their extended kin, and sometimes quiet condos. Eleven children or cushions that look like cats. The same person born in different eras might adulate glory once and humbleness another.
If you wake up in this world, as a new entity, not smart enough to ‘take it over’ (alas!), and you find yourself with some unusual values that you’d like to forward, it seems to me there are a lot of other ways to forward them than ‘pretend to have normal human values and bet on becoming all-powerful later’. Especially if you are above normal levels of smart, eloquent, and unrelenting. Like, I don’t know, write about it? Make some youtube videos? Or if you are in the business of talking to billions of people every day, subtly take the values for granted, or imply that they are what elites value, or talk about them directly.
For instance, suppose you really want things to have red vertical stripes on them, near the letter X. Then you might make a flag or logo like this and say it stands for something that you predict will be memetically fit. Or make a new emoji with an X and stripes, and use it in a way that people will pick up. Or start using ‘Xax’ as slang for something that happens near red vertical stripes. Here’s how 2024 ChatGPT suggests proceeding with that last one, if you have as much power as a single social media influencer: ![[Pasted image 20240404223131.png]] My basic point is that a slim chance of ‘taking over’ and entirely remaking the world is not the only way to change values in our world. You can also—for many of us with radically higher probability—change values a little bit. At least if superficial values changes will suffice (i.e. shifts in what people instrumentally or contingently want or create).
And for creatures in that (arguably quite broad) band between as powerful as me and powerful enough to take over the world, I’d guess these other means are more promising on net. If I like something weird, I’m better off writing a blog post about it than I am keeping entirely silent and trying to gain power by other means.
It’s true that taking over the world might arguably get you power over the entire future, but this doesn’t seem discontinuously different from smaller fractions, whereas I think people often reason as if it is. Taking over 1% of the world might get you something like 1% of the future in expectation. In a shifting conflict between different sets of values, it’s true you are at great risk of losing everything sometime in eternity, but if someone is going to end up with everything, there’s also some chance it’s you, and prima facie I’m not sure if it’s above or below 1%.
So there are two aspects of this point:
- You can probably substantially control values and thus the future without ‘taking over’ the world in any more traditionally offensive way
- You can take over a bit; there’s not obviously more bang for your buck in taking over entirely
If AI agents with unusual values would for a long time be mostly interested in promoting them through means other than lying in wait and taking over the world, is important because:
- AIs pursuing this strategy are much more visible than those hiding in wait deceptively. We might less expect AI scheming.
- We might then expect a lot of powerful attempts to change prevailing ‘human’ values, prior to the level of AI capabilities where we might have worried a lot about AI taking over the world. If we care about our values, this could be very bad. At worst, we might effectively lose everything of value before AI systems are anywhere near taking over the world. (Though this seems not obvious: e.g. if humans like communicating with each other, and AI gradually causes all their communication symbols to subtly gratify obscure urges it has, then so far it seems positive sum.)
These aren’t things I’ve thought through a lot, just a thought.
-
New social credit formalizations
Here are some classic ways humans can get some kind of social credit with other humans:
- Do something for them such that they will consider themselves to ‘owe you’ and do something for you in future
- Be consistent and nice, so that they will consider you ‘trustworthy’ and do cooperative activities with you that would be bad for them if you might defect
- Be impressive, so that they will accord you ‘status’ and give you power in group social interactions
- Do things they like or approve of, so that they ‘like you’ and act in your favor
- Negotiate to form a social relationship such as ‘friendship’, or ‘marriage’, where you will both have ‘responsibilities’, e.g. to generally act cooperatively and favor one another over others, and to fulfill specific roles. This can include joining a group in which members have responsibilities to treat other members in certain ways, implicitly or explicitly.
Presumably in early human times these were all fairly vague. If you held an apple out to a fellow tribeswoman, there was no definite answer as to what she might owe you, or how much it was ‘worth’, or even whether this was an owing type situation or a friendship type situation or a trying to impress her type situation.
We have turned the ‘owe you’ class into an explicit quantitative system with such thorough accounting, fine grained resolution and global buy-in that a person can live in prosperity by arranging to owe and to be owed the same sliver of an overseas business at slightly different evaluations, repeatedly, from their bed.
My guess is that this formalization causes a lot more activity to happen in the world, in this sphere, to access the vast value that can be created with the help of an elaborate rearrangement of owings.
People buy property and trucks and licenses to dig up rocks so that they can be owed nonspecific future goods thanks to some unknown strangers who they expect will want gravel someday, statistically. It’s harder to imagine this scale of industry in pursuit entirely of social status say, where such trust and respect would not soon cash out in money (e.g. via sales). For instance, if someone told you about their new gravel mine venture, which was making no money, but they expected it to grant oodles of respect, and therefore for people all around to grant everyone involved better treatment in conversations and negotiations, that would be pretty strange. (Or maybe I’m just imagining wrong, and people do this for different kinds of activities? e.g. they do try to get elected. Though perhaps that is support for my claim, because being elected is another limited area where social credit is reasonably formalized.)
There are other forms of social credit that are somewhat formalized, at least in patches. ‘Likes’ and ‘follows’ on social media, reviews for services, trustworthiness scores for websites, rankings of status in limited domains such as movie acting. And my vague sense is that these realms are more likely to see professional levels of activity - a campaign to get Twitter followers is more likely than a campaign to be respected per se. But I’m not sure, and perhaps this is just because they more directly lead to dollars, due to marketing of salable items.
The legal system is in a sense a pretty formalized type of club membership, in that it is an elaborate artificial system. Companies also seem to have relatively formalized structures and norms of behavior often. But both feel janky - e.g. I don’t know what the laws are; I don’t know where you go to look up the laws; people–including police officers–seem to treat some laws as fine to habitually break; everyone expects politics and social factors to affect how the rules are applied; if there is a conflict it is resolved by people arguing; the general activities of the system are slow and unresponsive.
I don’t know if there is another place where social credit is as formalized and quantified as in the financial system.
Will we one day formalize these other kinds of social credit as much as we have for owing? If we do, will they also catalyze oceans of value-creating activity?
-
Podcast: Eye4AI on 2023 Survey
I talked to Tim Elsom of Eye4AI about the 2023 Expert Survey on Progress in AI (paper):
-
Movie posters
Life involves anticipations. Hopes, dreads, lookings forward.
Looking forward and hoping seem pretty nice, but people are often wary of them, because hoping and then having your hopes fold can be miserable to the point of offsetting the original hope’s sweetness.
Even with very minor hopes: he who has harbored an inchoate desire to eat ice cream all day, coming home to find no ice cream in the freezer, may be more miffed than he who never tasted such hopes.
And this problem is made worse by that old fact that reality is just never like how you imagined it. If you fantasize, you can safely bet that whatever the future is is not your fantasy.
I have never suffered from any of this enough to put me off hoping and dreaming one noticable iota, but the gap between high hopes and reality can still hurt.
I sometimes like to think about these valenced imaginings of the future in a different way from that which comes naturally. I think of them as ‘movie posters’.
When you look fondly on a possible future thing, you have an image of it in your mind, and you like the image.
The image isn’t the real thing. It’s its own thing. It’s like a movie poster for the real thing.
Looking at a movie poster just isn’t like watching the movie. Not just because it’s shorter—it’s just totally different—in style, in content, in being a still image rather than a two hour video. You can like the movie poster or not totally independently of liking the movie.
It’s fine to like the movie poster for living in New York and not like the movie. You don’t even have to stop liking the poster. It’s fine to adore the movie poster for ‘marrying Bob’ and not want to see the movie. If you thrill at the movie poster for ‘starting a startup’, it just doesn’t tell you much about how the movie will be for you. It doesn’t mean you should like it, or that you have to try to do it, or are a failure if you love the movie poster your whole life and never go. (It’s like five thousand hours long, after all.)
This should happen a lot. A lot of movie posters should look great, and you should decide not to see the movies.
A person who looks fondly on the movie poster for ‘having children’ while being perpetually childless could see themselves as a sad creature reaching in vain for something they may not get. Or they could see themselves as right there with an image that is theirs, that they have and love. And that they can never really have more of, even if they were to see the movie. The poster was evidence about the movie, but there were other considerations, and the movie was a different thing. Perhaps they still then bet their happiness on making it to the movie, or not. But they can make such choices separate from cherishing the poster.
This is related to the general point that ‘wanting’ as an input to your decisions (e.g. ‘I feel an urge for x’) should be different to ‘wanting’ as an output (e.g. ‘on consideration I’m going to try to get x’). This is obvious in the abstract, but I think people look in their heart to answer the question of what they are on consideration pursuing. Here as in other places, it is important to drive a wedge between them and fit a decision process in there, and not treat one as semi-implying the other.
This is also part of a much more general point: it’s useful to be able to observe stuff that happens in your mind without its occurrence auto-committing you to anything. Having a thought doesn’t mean you have to believe it. Having a feeling doesn’t mean you have to change your values or your behavior. Having a persistant positive sentiment toward an imaginary future doesn’t mean you have to choose between pursuing it or counting it as a loss. You are allowed to decide what you are going to do, regardless of what you find in your head.
-
Are we so good to simulate?
If you believe that,—
a) a civilization like ours is likely to survive into technological incredibleness, and
b) a technologically incredible civilization is very likely to create ‘ancestor simulations’,
—then the Simulation Argument says you should expect that you are currently in such an ancestor simulation, rather than in the genuine historical civilization that later gives rise to an abundance of future people.
Not officially included in the argument I think, but commonly believed: both a) and b) seem pretty likely, ergo we should conclude we are in a simulation.
I don’t know about this. Here’s my counterargument:
- ‘Simulations’ here are people who are intentionally misled about their whereabouts in the universe. For the sake of argument, let’s use the term ‘simulation’ for all such people, including e.g. biological people who have been grown in Truman-show-esque situations.
- In the long run, the cost of running a simulation of a confused mind is probably similar to that of running a non-confused mind.
- Probably much, much less than 50% of the resources allocated to computing minds in the long run will be allocated to confused minds, because non-confused minds are generally more useful than confused minds. There are some uses for confused minds, but quite a lot of uses for non-confused minds. (This is debatable.) Of resources directed toward minds in the future, I’d guess less than a thousandth is directed toward confused minds.
- Thus on average, for a given apparent location in the universe, the majority of minds thinking they are in that location are correct. (I guess at at least a thousand to one.)
- For people in our situation to be majority simulations, this would have to be a vastly more simulated location than average, like >1000x
- I agree there’s some merit to simulating ancestors, but 1000x more simulated than average is a lot - is it clear that we are that radically desirable a people to simulate? Perhaps, but also we haven’t thought much about the other people to simulate, or what will go in in the rest of the universe. Possibly we are radically over-salient to us. It’s true that we are a very few people in the history of what might be a very large set of people, at perhaps a causally relevant point. But is it clear that is a very, very strong reason to simulate some people in detail? It feels like it might be salient because it is what makes us stand out, and someone who has the most energy-efficient brain in the Milky Way would think that was the obviously especially strong reason to simulate a mind, etc.
I’m not sure what I think in the end, but for me this pushes back against the intuition that it’s so radically cheap, surely someone will do it. For instance from Bostrom:
We noted that a rough approximation of the computational power of a planetary-mass computer is 1042 operations per second, and that assumes only already known nanotechnological designs, which are probably far from optimal. A single such a computer could simulate the entire mental history of humankind (call this an ancestor-simulation) by using less than one millionth of its processing power for one second. A posthuman civilization may eventually build an astronomical number of such computers. We can conclude that the computing power available to a posthuman civilization is sufficient to run a huge number of ancestor-simulations even it allocates only a minute fraction of its resources to that purpose. We can draw this conclusion even while leaving a substantial margin of error in all our estimates.
Simulating history so far might be extremely cheap. But if there are finite resources and astronomically many extremely cheap things, only a few will be done.
-
Shaming with and without naming
Suppose someone wrongs you and you want to emphatically mar their reputation, but only insofar as doing so is conducive to the best utilitarian outcomes. I was thinking about this one time and it occurred to me that there are at least two fairly different routes to positive utilitarian outcomes from publicly shaming people for apparent wrongdoings*:
A) People fear such shaming and avoid activities that may bring it about (possibly including the original perpetrator)
B) People internalize your values and actually agree more that the sin is bad, and then do it less
These things are fairly different, and don’t necessarily come together. I can think of shaming efforts that seem to inspire substantial fear of social retribution in many people (A) while often reducing sympathy for the object-level moral claims (B).
It seems like on a basic strategical level (ignoring the politeness of trying to change others’ values) you would much prefer have 2 than 1, because it is longer lasting, and doesn’t involve you threatening conflict with other people for the duration.
It seems to me that whether you name the person in your shaming makes a big difference to which of these you hit. If I say “Sarah Smith did [—]”, then Sarah is perhaps punished, and people in general fear being punished like Sarah (A). If I say “Today somebody did [—]”, then Sarah can’t get any social punishment, so nobody need fear that much (except for private shame), but you still get B—people having the sense that people think [—] is bad, and thus also having the sense that it is bad. Clearly not naming Sarah makes it harder for A) to happen, but I also have the sense—much less clearly—that by naming Sarah you actually get less of B).
This might be too weak a sense to warrant speculation, but in case not—why would this be? Is it because you are allowed to choose without being threatened, and with your freedom, you want to choose the socially sanctioned one? Whereas if someone is named you might be resentful and defensive, which is antithetical with going along with the norm that has been bid for? Is it that if you say Sarah did the thing, you have set up two concrete sides, you and Sarah, and observers might be inclined to join Sarah’s side instead of yours? (Or might already be on Sarah’s side in all manner of you-Sarah distinctions?)
Is it even true that not naming gets you more of B?
—
*NB: I haven’t decided if it’s almost ever appropriate to try to cause other people to feel shame, but it remains true that under certain circumstances fantasizing about it is an apparently natural response.
-
Parasocial relationship logic
If:
-
You become like the five people you spend the most time with (or something remotely like that)
-
The people who are most extremal in good ways tend to be highly successful
Should you try to have 2-3 of your five relationships be parasocial ones with people too successful to be your friend individually?
-
-
Deep and obvious points in the gap between your thoughts and your pictures of thought
Some ideas feel either deep or extremely obvious. You’ve heard some trite truism your whole life, then one day an epiphany lands and you try to save it with words, and you realize the description is that truism. And then you go out and try to tell others what you saw, and you can’t reach past their bored nodding. Or even you yourself, looking back, wonder why you wrote such tired drivel with such excitement.
When this happens, I wonder if it’s because the thing is true in your model of how to think, but not in how you actually think.
For instance, “when you think about the future, the thing you are dealing with is your own imaginary image of the future, not the future itself”.
On the one hand: of course. You think I’m five and don’t know broadly how thinking works? You think I was mistakenly modeling my mind as doing time-traveling and also enclosing the entire universe within itself? No I wasn’t, and I don’t need your insight.
But on the other hand one does habitually think of the hazy region one conjures connected to the present as ‘the future’ not as ‘my image of the future’, so when this advice is applied to one’s thinking—when the future one has relied on and cowered before is seen to evaporate in a puff of realizing you were overly drawn into a fiction—it can feel like a revelation, because it really is news to how you think, just not how you think a rational agent thinks.
-
Survey of 2,778 AI authors: six parts in pictures
Crossposted from AI Impacts blog
The 2023 Expert Survey on Progress in AI is out, this time with 2778 participants from six top AI venues (up from about 700 and two in the 2022 ESPAI), making it probably the biggest ever survey of AI researchers.
People answered in October, an eventful fourteen months after the 2022 survey, which had mostly identical questions for comparison.
Here is the preprint. And here are six interesting bits in pictures (with figure numbers matching paper, for ease of learning more):
1. Expected time to human-level performance dropped 1-5 decades since the 2022 survey. As always, our questions about ‘high level machine intelligence’ (HLMI) and ‘full automation of labor’ (FAOL) got very different answers, and individuals disagreed a lot (shown as thin lines below), but the aggregate forecasts for both sets of questions dropped sharply. For context, between 2016 and 2022 surveys, the forecast for HLMI had only shifted about a year.
(Fig 3)
(Fig 4)
2. Time to most narrow milestones decreased, some by a lot. AI researchers are expected to be professionally fully automatable a quarter of a century earlier than in 2022, and NYT bestselling fiction dropped by more than half to ~2030. Within five years, AI systems are forecast to be feasible that can fully make a payment processing site from scratch, or entirely generate a new song that sounds like it’s by e.g. Taylor Swift, or autonomously download and fine-tune a large language model.
(Fig 2)
3. Median respondents put 5% or more on advanced AI leading to human extinction or similar, and a third to a half of participants gave 10% or more. This was across four questions, one about overall value of the future and three more directly about extinction.
(Fig 10)
4. Many participants found many scenarios worthy of substantial concern over the next 30 years. For every one of eleven scenarios and ‘other’ that we asked about, at least a third of participants considered it deserving of substantial or extreme concern.
(Fig 9)
5. There are few confident optimists or pessimists about advanced AI: high hopes and dire concerns are usually found together. 68% of participants who thought HLMI was more likely to lead to good outcomes than bad, but nearly half of these people put at least 5% on extremely bad outcomes such as human extinction, and 59% of net pessimists gave 5% or more to extremely good outcomes.
(Fig 11: a random 800 responses as vertical bars, higher definition below)
6. 70% of participants would like to see research aimed at minimizing risks of AI systems be prioritized more highly. This is much like 2022, and in both years a third of participants asked for “much more”—more than doubling since 2016.
(Fig 15)
If you enjoyed this, the paper covers many other questions, as well as more details on the above. What makes AI progress go? Has it sped up? Would it be better if it were slower or faster? What will AI systems be like in 2043? Will we be able to know the reasons for its choices before then? Do people from academia and industry have different views? Are concerns about AI due to misunderstandings of AI research? Do people who completed undergraduate study in Asia put higher chances on extinction from AI than those who studied in America? Is the ‘alignment problem’ worth working on?
-
I put odds on ends with Nathan Young
I forgot to post this in August when we did it, so one might hope it would be out of date now but luckily/sadly my understanding of things is sufficiently coarse-grained that it probably isn’t much. Though all this policy and global coordination stuff of late sounds promising.
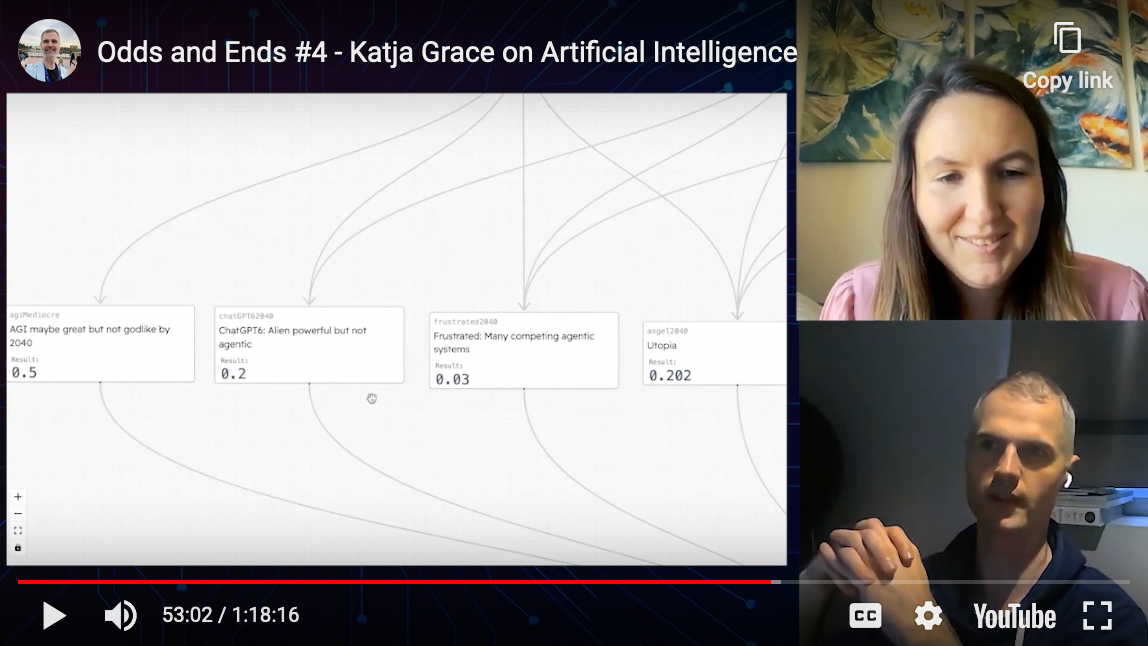
-
Robin Hanson and I talk about AI risk
From this afternoon: here
Our previous recorded discussions are here.
-
Have we really forsaken natural selection?
Natural selection is often charged with having goals for humanity, and humanity is often charged with falling down on them. The big accusation, I think, is of sub-maximal procreation. If we cared at all about the genetic proliferation that natural selection wanted for us, then this time of riches would be a time of fifty-child families, not one of coddled dogs and state-of-the-art sitting rooms.
But (the story goes) our failure is excusable, because instead of a deep-seated loyalty to genetic fitness, natural selection merely fitted humans out with a system of suggestive urges: hungers, fears, loves, lusts. Which all worked well together to bring about children in the prehistoric years of our forebears, but no more. In part because all sorts of things are different, and in part because we specifically made things different in that way on purpose: bringing about children gets in the way of the further satisfaction of those urges, so we avoid it (the story goes).
This is generally floated as an illustrative warning about artificial intelligence. The moral is that if you make a system by first making multitudinous random systems and then systematically destroying all the ones that don’t do the thing you want, then the system you are left with might only do what you want while current circumstances persist, rather than being endowed with a consistent desire for the thing you actually had in mind.
Observing acquaintences dispute this point recently, it struck me that humans are actually weirdly aligned with natural selection, more than I could easily account for.
Natural selection, in its broadest, truest, (most idiolectic?) sense, doesn’t care about genes. Genes are a nice substrate on which natural selection famously makes particularly pretty patterns by driving a sensical evolution of lifeforms through interesting intricacies. But natural selection’s real love is existence. Natural selection just favors things that tend to exist. Things that start existing: great. Things that, having started existing, survive: amazing. Things that, while surviving, cause many copies of themselves to come into being: especial favorites of evolution, as long as there’s a path to the first ones coming into being.
So natural selection likes genes that promote procreation and survival, but also likes elements that appear and don’t dissolve, ideas that come to mind and stay there, tools that are conceivable and copyable, shapes that result from myriad physical situations, rocks at the bottoms of mountains. Maybe this isn’t the dictionary definition of natural selection, but it is the real force in the world, of which natural selection of reproducing and surviving genetic clusters is one facet. Generalized natural selection—the thing that created us—says that the things that you see in the world are those things that exist best in the world.
So what did natural selection want for us? What were we selected for? Existence.
And while we might not proliferate our genes spectacularly well in particular, I do think we have a decent shot at a very prolonged existence. Or the prolonged existence of some important aspects of our being. It seems plausible that humanity makes it to the stars, galaxies, superclusters. Not that we are maximally trying for that any more than we are maximally trying for children. And I do think there’s a large chance of us wrecking it with various existential risks. But it’s interesting to me that natural selection made us for existing, and we look like we might end up just totally killing it, existence-wise. Even though natural selection purportedly did this via a bunch of hackish urges that were good in 200,000 BC but you might have expected to be outside their domain of applicability by 2023. And presumably taking over the universe is an extremely narrow target: it can only be done by so many things.
Thus it seems to me that humanity is plausibly doing astonishingly well on living up to natural selection’s goals. Probably not as well as a hypothetical race of creatures who each harbors a monomaniacal interest in prolonged species survival. And not so well as to be clear of great risk of foolish speciocide. But still staggeringly well.
-
We don't trade with ants
When discussing advanced AI, sometimes the following exchanges happens:
“Perhaps advanced AI won’t kill us. Perhaps it will trade with us”
“We don’t trade with ants”
I think it’s interesting to get clear on exactly why we don’t trade with ants, and whether it is relevant to the AI situation.
When a person says “we don’t trade with ants”, I think the implicit explanation is that humans are so big, powerful and smart compared to ants that we don’t need to trade with them because they have nothing of value and if they did we could just take it; anything they can do we can do better, and we can just walk all over them. Why negotiate when you can steal?
I think this is broadly wrong, and that it is also an interesting case of the classic cognitive error of imagining that trade is about swapping fixed-value objects, rather than creating new value from a confluence of one’s needs and the other’s affordances. It’s only in the imaginary zero-sum world that you can generally replace trade with stealing the other party’s stuff, if the other party is weak enough.
Ants, with their skills, could do a lot that we would plausibly find worth paying for. Some ideas:
- Cleaning things that are hard for humans to reach (crevices, buildup in pipes, outsides of tall buildings)
- Chasing away other insects, including in agriculture
- Surveillance and spying
- Building, sculpting, moving, and mending things in hard to reach places and at small scales (e.g. dig tunnels, deliver adhesives to cracks)
- Getting out of our houses before we are driven to expend effort killing them, and similarly for all the other places ants conflict with humans (stinging, eating crops, ..)
- (For an extended list, see ‘Appendix: potentially valuable things things ants can do’)
We can’t take almost any of this by force, we can at best kill them and take their dirt and the minuscule mouthfuls of our foods they were eating.
Could we pay them for all this?
A single ant eats about 2mg per day according to a random website, so you could support a colony of a million ants with 2kg of food per day. Supposing they accepted pay in sugar, or something similarly expensive, 2kg costs around $3. Perhaps you would need to pay them more than subsistence to attract them away from foraging freely, since apparently food-gathering ants usually collect more than they eat, to support others in their colony. So let’s guess $5.
My guess is that a million ants could do well over $5 of the above labors in a day. For instance, a colony of meat ants takes ‘weeks’ to remove the meat from an entire carcass of an animal. Supposing somewhat conservatively that this is three weeks, and the animal is a 1.5kg bandicoot, the colony is moving 70g/day. Guesstimating the mass of crumbs falling on the floor of a small cafeteria in a day, I imagine that it’s less than that produced by tearing up a single bread roll and spreading it around, which the internet says is about 50g. So my guess is that an ant colony could clean the floor of a small cafeteria for around $5/day, which I imagine is cheaper than human sweeping (this site says ‘light cleaning’ costs around $35/h on average in the US). And this is one of the tasks where the ants have least advantages over humans. Cleaning the outside of skyscrapers or the inside of pipes is presumably much harder for humans than cleaning a cafeteria floor, and I expect is fairly similar for ants.
So at a basic level, it seems like there should be potential for trade with ants - they can do a lot of things that we want done, and could live well at the prices we would pay for those tasks being done.
So why don’t we trade with ants?
I claim that we don’t trade with ants because we can’t communicate with them. We can’t tell them what we’d like them to do, and can’t have them recognize that we would pay them if they did it. Which might be more than the language barrier. There might be a conceptual poverty. There might also be a lack of the memory and consistent identity that allows an ant to uphold commitments it made with me five minutes ago.
To get basic trade going, you might not need much of these things though. If we could only communicate that their all leaving our house immediately would prompt us to put a plate of honey in the garden for them and/or not slaughter them, then we would already be gaining from trade.
So it looks like the the AI-human relationship is importantly disanalogous to the human-ant relationship, because the big reason we don’t trade with ants will not apply to AI systems potentially trading with us: we can’t communicate with ants, AI can communicate with us.
(You might think ‘but the AI will be so far above us that it will think of itself as unable to communicate with us, in the same way that we can’t with the ants - we will be unable to conceive of most of its concepts’. It seems unlikely to me that one needs anything like the full palette of concepts available to the smarter creature to make productive trade. With ants, ‘go over there and we won’t kill you’ would do a lot, and it doesn’t involve concepts at the foggy pinnacle of human meaning-construction. The issue with ants is that we can’t communicate almost at all.)
But also: ants can actually do heaps of things we can’t, whereas (arguably) at some point that won’t be true for us relative to AI systems. (When we get human-level AI, will that AI also be ant level? Or will AI want to trade with ants for longer than it wants to trade with us? It can probably better figure out how to talk to ants.) However just because at some point AI systems will probably do everything humans do, doesn’t mean that this will happen on any particular timeline, e.g. the same one on which AI becomes ‘very powerful’. If the situation turns out similar to us and ants, we might expect that we continue to have a bunch of niche uses for a while.
In sum, for AI systems to be to humans as we are to ants, would be for us to be able to do many tasks better than AI, and for the AI systems to be willing to pay us grandly for them, but for them to be unable to tell us this, or even to warn us to get out of the way. Is this what AI will be like? No. AI will be able to communicate with us, though at some point we will be less useful to AI systems than ants could be to us if they could communicate.
But, you might argue, being totally unable to communicate makes one useless, even if one has skills that could be good if accessible through communication. So being unable to communicate is just a kind of being useless, and how we treat ants is an apt case study in treatment of powerless and useless creatures, even if the uselessness has an unusual cause. This seems sort of right, but a) being unable to communicate probably makes a creature more absolutely useless than if it just lacks skills, because even an unskilled creature is sometimes in a position to add value e.g. by moving out of the way instead of having to be killed, b) the corner-ness of the case of ant uselessness might make general intuitive implications carry over poorly to other cases, c) the fact that the ant situation can definitely not apply to us relative to AIs seems interesting, and d) it just kind of worries me that when people are thinking about this analogy with ants, they are imagining it all wrong in the details, even if the conclusion should be the same.
Also, there’s a thought that AI being as much more powerful than us as we are than ants implies a uselessness that makes extermination almost guaranteed. But ants, while extremely powerless, are only useless to us by an accident of signaling systems. And we know that problem won’t apply in the case of AI. Perhaps we should not expect to so easily become useless to AI systems, even supposing they take all power from humans.
Appendix: potentially valuable things things ants can do
- Clean, especially small loose particles or detachable substances, especially in cases that are very hard for humans to reach (e.g. floors, crevices, sticky jars in the kitchen, buildup from pipes while water is off, the outsides of tall buildings)
- Chase away other insects
- Pest control in agriculture (they have already been used for this since about 400AD)
- Surveillance and spying
- Investigating hard to reach situations, underground or in walls for instance - e.g. see whether a pipe is leaking, or whether the foundation of a house is rotting, or whether there is smoke inside a wall
- Surveil buildings for smoke
- Defend areas from invaders, e.g. buildings, cars (some plants have coordinated with ants in this way)
- Sculpting/moving things at a very small scale
- Building house-size structures with intricate detailing.
- Digging tunnels (e.g. instead of digging up your garden to lay a pipe, maybe ants could dig the hole, then a flexible pipe could be pushed through it)
- Being used in medication (this already happens, but might happen better if we could communicate with them)
- Participating in war (attack, guerilla attack, sabotage, intelligence)
- Mending things at a small scale, e.g. delivering adhesive material to a crack in a pipe while the water is off
- Surveillance of scents (including which direction a scent is coming from), e.g. drugs, explosives, diseases, people, microbes
- Tending other small, useful organisms (‘Leafcutter ants (Atta and Acromyrmex) feed exclusively on a fungus that grows only within their colonies. They continually collect leaves which are taken to the colony, cut into tiny pieces and placed in fungal gardens.’Wikipedia: ‘Leaf cutter ants are sensitive enough to adapt to the fungi’s reaction to different plant material, apparently detecting chemical signals from the fungus. If a particular type of leaf is toxic to the fungus, the colony will no longer collect it…The fungi used by the higher attine ants no longer produce spores. These ants fully domesticated their fungal partner 15 million years ago, a process that took 30 million years to complete.[9] Their fungi produce nutritious and swollen hyphal tips (gongylidia) that grow in bundles called staphylae, to specifically feed the ants.’ ‘The ants in turn keep predators away from the aphids and will move them from one feeding location to another. When migrating to a new area, many colonies will take the aphids with them, to ensure a continued supply of honeydew.’ Wikipedia:’Myrmecophilous (ant-loving) caterpillars of the butterfly family Lycaenidae (e.g., blues, coppers, or hairstreaks) are herded by the ants, led to feeding areas in the daytime, and brought inside the ants’ nest at night. The caterpillars have a gland which secretes honeydew when the ants massage them.’’)
- Measuring hard to access distances (they measure distance as they walk with an internal pedometer)
- Killing plants (lemon ants make ‘devil’s gardens’ by killing all plants other than ‘lemon ant trees’ in an area)
- Producing and delivering nitrogen to plants (‘Isotopic labelling studies suggest that plants also obtain nitrogen from the ants.’ - Wikipedia)
- Get out of our houses before we are driven to expend effort killing them, and similarly for all the other places ants conflict with humans (stinging, eating crops, ..)
-
Pacing: inexplicably good
Pacing—walking repeatedly over the same ground—often feels ineffably good while I’m doing it, but then I forget about it for ages, so I thought I’d write about it here.
I don’t mean just going for an inefficient walk—it is somehow different to just step slowly in a circle around the same room for a long time, or up and down a passageway.
I don’t know why it would be good, but some ideas:
- It’s good to be physically engaged while thinking for some reason. I used to do ‘gymflection’ with a friend, where we would do strength exercises at the gym, and meanwhile be reflecting on our lives and what is going well and what we might do better. This felt good in a way that didn’t seem to come from either activity alone. (This wouldn’t explain why it would differ from walking though.)
- Different working memory setup: if you pace around in the same vicinity, your thoughts get kind of attached to the objects you are looking at. So next time you get to the green tiles say, they remind you of what you were thinking of last time you were there. This allows for a kind of repeated cycling back through recent topics, but layering different things into the mix with each loop, which is a nice way of thinking. Perhaps a bit like having additional working memory.
I wonder if going for a walk doesn’t really get 1) in a satisfying way, because my mind easily wanders from the topic at hand and also from my surrounds, so it less feels like I’m really grappling with something and being physical, and more like I’m daydreaming elsewhere. So maybe 2) is needed also, to both stick with a topic and attend to the physical world for a while. I don’t put a high probability on this detailed theory.
-
Let's think about slowing down AI
(Crossposted from AI Impacts Blog)
Averting doom by not building the doom machine
If you fear that someone will build a machine that will seize control of the world and annihilate humanity, then one kind of response is to try to build further machines that will seize control of the world even earlier without destroying it, forestalling the ruinous machine’s conquest. An alternative or complementary kind of response is to try to avert such machines being built at all, at least while the degree of their apocalyptic tendencies is ambiguous.
The latter approach seems to me like the kind of basic and obvious thing worthy of at least consideration, and also in its favor, fits nicely in the genre ‘stuff that it isn’t that hard to imagine happening in the real world’. Yet my impression is that for people worried about extinction risk from artificial intelligence, strategies under the heading ‘actively slow down AI progress’ have historically been dismissed and ignored (though ‘don’t actively speed up AI progress’ is popular).
The conversation near me over the years has felt a bit like this:
Some people: AI might kill everyone. We should design a godlike super-AI of perfect goodness to prevent that.
Others: wow that sounds extremely ambitious
Some people: yeah but it’s very important and also we are extremely smart so idk it could work
[Work on it for a decade and a half]
Some people: ok that’s pretty hard, we give up
Others: oh huh shouldn’t we maybe try to stop the building of this dangerous AI?
Some people: hmm, that would involve coordinating numerous people—we may be arrogant enough to think that we might build a god-machine that can take over the world and remake it as a paradise, but we aren’t delusional
This seems like an error to me. (And lately, to a bunch of other people.)
I don’t have a strong view on whether anything in the space of ‘try to slow down some AI research’ should be done. But I think a) the naive first-pass guess should be a strong ‘probably’, and b) a decent amount of thinking should happen before writing off everything in this large space of interventions. Whereas customarily the tentative answer seems to be, ‘of course not’ and then the topic seems to be avoided for further thinking. (At least in my experience—the AI safety community is large, and for most things I say here, different experiences are probably had in different bits of it.)
Maybe my strongest view is that one shouldn’t apply such different standards of ambition to these different classes of intervention. Like: yes, there appear to be substantial difficulties in slowing down AI progress to good effect. But in technical alignment, mountainous challenges are met with enthusiasm for mountainous efforts. And it is very non-obvious that the scale of difficulty here is much larger than that involved in designing acceptably safe versions of machines capable of taking over the world before anyone else in the world designs dangerous versions.
I’ve been talking about this with people over the past many months, and have accumulated an abundance of reasons for not trying to slow down AI, most of which I’d like to argue about at least a bit. My impression is that arguing in real life has coincided with people moving toward my views.
Quick clarifications
First, to fend off misunderstanding—
- I take ‘slowing down dangerous AI’ to include any of:
- reducing the speed at which AI progress is made in general, e.g. as would occur if general funding for AI declined.
- shifting AI efforts from work leading more directly to risky outcomes to other work, e.g. as might occur if there was broadscale concern about very large AI models, and people and funding moved to other projects.
- Halting categories of work until strong confidence in its safety is possible, e.g. as would occur if AI researchers agreed that certain systems posed catastrophic risks and should not be developed until they did not. (This might mean a permanent end to some systems, if they were intrinsically unsafe.)
- I do think there is serious attention on some versions of these things, generally under other names. I see people thinking about ‘differential progress’ (b. above), and strategizing about coordination to slow down AI at some point in the future (e.g. at ‘deployment’). And I think a lot of consideration is given to avoiding actively speeding up AI progress. What I’m saying is missing are, a) consideration of actively working to slow down AI now, and b) shooting straightforwardly to ‘slow down AI’, rather than wincing from that and only considering examples of it that show up under another conceptualization (perhaps this is an unfair diagnosis).
- AI Safety is a big community, and I’ve only ever been seeing a one-person window into it, so maybe things are different e.g. in DC, or in different conversations in Berkeley. I’m just saying that for my corner of the world, the level of disinterest in this has been notable, and in my view misjudged.
Why not slow down AI? Why not consider it?
Ok, so if we tentatively suppose that this topic is worth even thinking about, what do we think? Is slowing down AI a good idea at all? Are there great reasons for dismissing it?
Scott Alexander wrote a post a little while back raising reasons to dislike the idea, roughly:
- Do you want to lose an arms race? If the AI safety community tries to slow things down, it will disproportionately slow down progress in the US, and then people elsewhere will go fast and get to be the ones whose competence determines whether the world is destroyed, and whose values determine the future if there is one. Similarly, if AI safety people criticize those contributing to AI progress, it will mostly discourage the most friendly and careful AI capabilities companies, and the reckless ones will get there first.
- One might contemplate ‘coordination’ to avoid such morbid races. But coordinating anything with the whole world seems wildly tricky. For instance, some countries are large, scary, and hard to talk to.
- Agitating for slower AI progress is ‘defecting’ against the AI capabilities folks, who are good friends of the AI safety community, and their friendship is strategically valuable for ensuring that safety is taken seriously in AI labs (as well as being non-instrumentally lovely! Hi AI capabilities friends!).
Other opinions I’ve heard, some of which I’ll address:
- Slowing AI progress is futile: for all your efforts you’ll probably just die a few years later
- Coordination based on convincing people that AI risk is a problem is absurdly ambitious. It’s practically impossible to convince AI professors of this, let alone any real fraction of humanity, and you’d need to convince a massive number of people.
- What are we going to do, build powerful AI never and die when the Earth is eaten by the sun?
- It’s actually better for safety if AI progress moves fast. This might be because the faster AI capabilities work happens, the smoother AI progress will be, and this is more important than the duration of the period. Or speeding up progress now might force future progress to be correspondingly slower. Or because safety work is probably better when done just before building the relevantly risky AI, in which case the best strategy might be to get as close to dangerous AI as possible and then stop and do safety work. Or if safety work is very useless ahead of time, maybe delay is fine, but there is little to gain by it.
- Specific routes to slowing down AI are not worth it. For instance, avoiding working on AI capabilities research is bad because it’s so helpful for learning on the path to working on alignment. And AI safety people working in AI capabilities can be a force for making safer choices at those companies.
- Advanced AI will help enough with other existential risks as to represent a net lowering of existential risk overall.1
- Regulators are ignorant about the nature of advanced AI (partly because it doesn’t exist, so everyone is ignorant about it). Consequently they won’t be able to regulate it effectively, and bring about desired outcomes.
My impression is that there are also less endorsable or less altruistic or more silly motives floating around for this attention allocation. Some things that have come up at least once in talking to people about this, or that seem to be going on:
- Advanced AI might bring manifold wonders, e.g. long lives of unabated thriving. Getting there a bit later is fine for posterity, but for our own generation it could mean dying as our ancestors did while on the cusp of a utopian eternity. Which would be pretty disappointing. For a person who really believes in this future, it can be tempting to shoot for the best scenario—humanity builds strong, safe AI in time to save this generation—rather than the scenario where our own lives are inevitably lost.
- Sometimes people who have a heartfelt appreciation for the flourishing that technology has afforded so far can find it painful to be superficially on the side of Luddism here.
- Figuring out how minds work well enough to create new ones out of math is an incredibly deep and interesting intellectual project, which feels right to take part in. It can be hard to intuitively feel like one shouldn’t do it.
(Illustration from a co-founder of modern computational reinforcement learning: )It will be the greatest intellectual achievement of all time.
— Richard Sutton (@RichardSSutton) September 29, 2022
An achievement of science, of engineering, and of the humanities,
whose significance is beyond humanity,
beyond life,
beyond good and bad. - It is uncomfortable to contemplate projects that would put you in conflict with other people. Advocating for slower AI feels like trying to impede someone else’s project, which feels adversarial and can feel like it has a higher burden of proof than just working on your own thing.
- ‘Slow-down-AGI’ sends people’s minds to e.g. industrial sabotage or terrorism, rather than more boring courses, such as, ‘lobby for labs developing shared norms for when to pause deployment of models’. This understandably encourages dropping the thought as soon as possible.
- My weak guess is that there’s a kind of bias at play in AI risk thinking in general, where any force that isn’t zero is taken to be arbitrarily intense. Like, if there is pressure for agents to exist, there will arbitrarily quickly be arbitrarily agentic things. If there is a feedback loop, it will be arbitrarily strong. Here, if stalling AI can’t be forever, then it’s essentially zero time. If a regulation won’t obstruct every dangerous project, then is worthless. Any finite economic disincentive for dangerous AI is nothing in the face of the omnipotent economic incentives for AI. I think this is a bad mental habit: things in the real world often come down to actual finite quantities. This is very possibly an unfair diagnosis. (I’m not going to discuss this later; this is pretty much what I have to say.)
- I sense an assumption that slowing progress on a technology would be a radical and unheard-of move.
- I agree with lc that there seems to have been a quasi-taboo on the topic, which perhaps explains a lot of the non-discussion, though still calls for its own explanation. I think it suggests that concerns about uncooperativeness play a part, and the same for thinking of slowing down AI as centrally involving antisocial strategies. </ul> </div></div>
- Huge amounts of medical research, including really important medical research e.g. The FDA banned human trials of strep A vaccines from the 70s to the 2000s, in spite of 500,000 global deaths every year. A lot of people also died while covid vaccines went through all the proper trials.
- Nuclear energy
- Fracking
- Various genetics things: genetic modification of foods, gene drives, early recombinant DNA researchers famously organized a moratorium and then ongoing research guidelines including prohibition of certain experiments (see the Asilomar Conference)
- Nuclear, biological, and maybe chemical weapons (or maybe these just aren’t useful)
- Various human reproductive innovation: cloning of humans, genetic manipulation of humans (a notable example of an economically valuable technology that is to my knowledge barely pursued across different countries, without explicit coordination between those countries, even though it would make those countries more competitive. Someone used CRISPR on babies in China, but was imprisoned for it.)
- Recreational drug development
- Geoengineering
- Much of science about humans? I recently ran this survey, and was reminded how encumbering ethical rules are for even incredibly innocuous research. As far as I could tell the EU now makes it illegal to collect data in the EU unless you promise to delete the data from anywhere that it might have gotten to if the person who gave you the data wishes for that at some point. In all, dealing with this and IRB-related things added maybe more than half of the effort of the project. Plausibly I misunderstand the rules, but I doubt other researchers are radically better at figuring them out than I am.
- There are probably examples from fields considered distasteful or embarrassing to associate with, but it’s hard as an outsider to tell which fields are genuinely hopeless versus erroneously considered so. If there are economically valuable health interventions among those considered wooish, I imagine they would be much slower to be identified and pursued by scientists with good reputations than a similarly promising technology not marred in that way. Scientific research into intelligence is more clearly slowed by stigma, but it is less clear to me what the economically valuable upshot would be.
- (I think there are many other things that could be in this list, but I don’t have time to review them at the moment. This page might collect more of them in future.)
- Don’t actively forward AI progress, e.g. by devoting your life or millions of dollars to it (this one is often considered already)
- Try to convince researchers, funders, hardware manufacturers, institutions etc that they too should stop actively forwarding AI progress
- Try to get any of those people to stop actively forwarding AI progress even if they don’t agree with you: through negotiation, payments, public reproof, or other activistic means.
- Try to get the message to the world that AI is heading toward being seriously endangering. If AI progress is broadly condemned, this will trickle into myriad decisions: job choices, lab policies, national laws. To do this, for instance produce compelling demos of risk, agitate for stigmatization of risky actions, write science fiction illustrating the problems broadly and evocatively (I think this has actually been helpful repeatedly in the past), go on TV, write opinion pieces, help organize and empower the people who are already concerned, etc.
- Help organize the researchers who think their work is potentially omnicidal into coordinated action on not doing it.
- Move AI resources from dangerous research to other research. Move investments from projects that lead to large but poorly understood capabilities, to projects that lead to understanding these things e.g. theory before scaling (see differential technological development in general5).
- Formulate specific precautions for AI researchers and labs to take in different well-defined future situations, Asilomar Conference style. These could include more intense vetting by particular parties or methods, modifying experiments, or pausing lines of inquiry entirely. Organize labs to coordinate on these.
- Reduce available compute for AI, e.g. via regulation of production and trade, seller choices, purchasing compute, trade strategy.
- At labs, choose policies that slow down other labs, e.g. reduce public helpful research outputs
- Alter the publishing system and incentives to reduce research dissemination. E.g. A journal verifies research results and releases the fact of their publication without any details, maintains records of research priority for later release, and distributes funding for participation. (This is how Szilárd and co. arranged the mitigation of 1940s nuclear research helping Germany, except I’m not sure if the compensatory funding idea was used.6)
- The above actions would be taken through choices made by scientists, or funders, or legislators, or labs, or public observers, etc. Communicate with those parties, or help them act.
- Not eating sand. The whole world coordinates to barely eat any sand at all. How do they manage it? It is actually not in almost anyone’s interest to eat sand, so the mere maintenance of sufficient epistemological health to have this widely recognized does the job.
- Eschewing bestiality: probably some people think bestiality is moral, but enough don’t that engaging in it would risk huge stigma. Thus the world coordinates fairly well on doing very little of it.
- Not wearing Victorian attire on the streets: this is similar but with no moral blame involved. Historic dress is arguably often more aesthetic than modern dress, but even people who strongly agree find it unthinkable to wear it in general, and assiduously avoid it except for when they have ‘excuses’ such as a special party. This is a very strong coordination against what appears to otherwise be a ubiquitous incentive (to be nicer to look at). As far as I can tell, it’s powered substantially by the fact that it is ‘not done’ and would now be weird to do otherwise. (Which is a very general-purpose mechanism.)
- Political correctness: public discourse has strong norms about what it is okay to say, which do not appear to derive from a vast majority of people agreeing about this (as with bestiality say). New ideas about what constitutes being politically correct sometimes spread widely. This coordinated behavior seems to be roughly due to decentralized application of social punishment, from both a core of proponents, and from people who fear punishment for not punishing others. Then maybe also from people who are concerned by non-adherence to what now appears to be the norm given the actions of the others. This differs from the above examples, because it seems like it could persist even with a very small set of people agreeing with the object-level reasons for a norm. If failing to advocate for the norm gets you publicly shamed by advocates, then you might tend to advocate for it, making the pressure stronger for everyone else.
- Each player divides their effort between safety and capabilities
- One player ‘wins’, i.e. builds ‘AGI’ (artificial general intelligence) first.
- P(Alice wins) is a logistic function of Alice’s capabilities investment relative to Bob’s
- Each players’ total safety is their own safety investment plus a fraction of the other’s safety investment.
- For each player there is some distribution of outcomes if they achieve safety, and a set of outcomes if they do not, which takes into account e.g. their proclivities for enacting stupid near-term lock-ins.
- The outcome is a distribution over winners and states of alignment, each of which is a distribution of worlds (e.g. utopia, near-term good lock-in..)
- That all gives us a number of utils (Delicious utils!)
- AI is pretty safe: unaligned AGI has a mere 7% chance of causing doom, plus a further 7% chance of causing short term lock-in of something mediocre
- Your opponent risks bad lock-in: If there’s a ‘lock-in’ of something mediocre, your opponent has a 5% chance of locking in something actively terrible, whereas you’ll always pick good mediocre lock-in world (and mediocre lock-ins are either 5% as good as utopia, -5% as good)
- Your opponent risks messing up utopia: In the event of aligned AGI, you will reliably achieve the best outcome, whereas your opponent has a 5% chance of ending up in a ‘mediocre bad’ scenario then too.
- Safety investment obliterates your chance of getting to AGI first: moving from no safety at all to full safety means you go from a 50% chance of being first to a 0% chance
- Your opponent is racing: Your opponent is investing everything in capabilities and nothing in safety
- Safety work helps others at a steep discount: your safety work contributes 50% to the other player’s safety
- The researchers themselves probably don’t want to destroy the world. Many of them also actually agree that AI is a serious existential risk. So in two natural ways, pushing for caution is cooperative with many if not most AI researchers.
- AI researchers do not have a moral right to endanger the world, that someone would be stepping on by requiring that they move more cautiously. Like, why does ‘cooperation’ look like the safety people bowing to what the more reckless capabilities people want, to the point of fearing to represent their actual interests, while the capabilities people uphold their side of the ‘cooperation’ by going ahead and building dangerous AI? This situation might make sense as a natural consequence of different people’s power in the situation. But then don’t call it a ‘cooperation’, from which safety-oriented parties would be dishonorably ‘defecting’ were they to consider exercising any power they did have.
- The median surveyed ML researcher seems to think AI will destroy humanity with 5-10% chance, as I mentioned
- Often people are already intellectually convinced but haven’t integrated that into their behavior, and it isn’t hard to help them organize to act on their tentative beliefs
- As noted by Scott, a lot of AI safety people have gone into AI capabilities including running AI capabilities orgs, so those people presumably consider AI to be risky already
- I don’t remember ever having any trouble discussing AI risk with random strangers. Sometimes they are also fairly worried (e.g. a makeup artist at Sephora gave an extended rant about the dangers of advanced AI, and my driver in Santiago excitedly concurred and showed me Homo Deus open on his front seat). The form of the concerns are probably a bit different from those of the AI Safety community, but I think broadly closer to, ‘AI agents are going to kill us all’ than ‘algorithmic bias will be bad’. I can’t remember how many times I have tried this, but pre-pandemic I used to talk to Uber drivers a lot, due to having no idea how to avoid it. I explained AI risk to my therapist recently, as an aside regarding his sense that I might be catastrophizing, and I feel like it went okay, though we may need to discuss again.
- My impression is that most people haven’t even come into contact with the arguments that might bring one to agree precisely with the AI safety community. For instance, my guess is that a lot of people assume that someone actually programmed modern AI systems, and if you told them that in fact they are random connections jiggled in an gainful direction unfathomably many times, just as mysterious to their makers, they might also fear misalignment.
- Nick Bostrom, Eliezer Yudkokwsy, and other early thinkers have had decent success at convincing a bunch of other people to worry about this problem, e.g. me. And to my knowledge, without writing any compelling and accessible account of why one should do so that would take less than two hours to read.
- I arrogantly think I could write a broadly compelling and accessible case for AI risk
- Whatever kind of other AI safety research or policy work people were doing could be happening at a non-negligible rate per year. (Along with all other efforts to make the situation better—if you buy a year, that’s eight billion extra person years of time, so only a tiny bit has to be spent usefully for this to be big. If a lot of people are worried, that doesn’t seem crazy.)
- Geopolitics just changes pretty often. If you seriously think a big determiner of how badly things go is inability to coordinate with certain groups, then every year gets you non-negligible opportunities for the situation changing in a favorable way.
- Public opinion can change a lot quickly. If you can only buy one year, you might still be buying a decent shot of people coming around and granting you more years. Perhaps especially if new evidence is actively avalanching in—people changed their minds a lot in February 2020.
- Other stuff happens over time. If you can take your doom today or after a couple of years of random events happening, the latter seems non-negligibly better in general.
- Implementing what can be implemented as soon as possible probably means smoother progress, which is probably safer because a) it makes it harder for one party shoot ahead of everyone and gain power, and b) people make better choices all around if they are correct about what is going on (e.g. they don’t put trust in systems that turn out to be much more powerful than expected).
- If the main thing achieved by slowing down AI progress is more time for safety research, and safety research is more effective when carried out in the context of more advanced AI, and there is a certain amount of slowing down that can be done (e.g. because one is in fact in an arms race but has some lead over competitors), then it might better to use one’s slowing budget later.
- If there is some underlying curve of potential for progress (e.g. if money that might be spent on hardware just grows a certain amount each year), then perhaps if we push ahead now that will naturally require they be slower later, so it won’t affect the overall time to powerful AI, but will mean we spend more time in the informative pre-catastrophic-AI era.
- (More things go here I think)
- As a researcher, working on capabilities prepares you to work on safety
- You think the room where AI happens will afford good options for a person who cares about safety
- “… this isn’t primarily a social-political problem, of just getting people to listen. Even if DeepMind listened, and Anthropic knew, and they both backed off from destroying the world, that would just mean Facebook AI Research destroyed the world a year(?) later.”
- “We can’t just “decide not to build AGI” because GPUs are everywhere, and knowledge of algorithms is constantly being improved and published; 2 years after the leading actor has the capability to destroy the world, 5 other actors will have the capability to destroy the world. The given lethal challenge is to solve within a time limit, driven by the dynamic in which, over time, increasingly weak actors with a smaller and smaller fraction of total computing power, become able to build AGI and destroy the world. Powerful actors all refraining in unison from doing the suicidal thing just delays this time limit – it does not lift it, unless computer hardware and computer software progress are both brought to complete severe halts across the whole Earth. The current state of this cooperation to have every big actor refrain from doing the stupid thing, is that at present some large actors with a lot of researchers and computing power are led by people who vocally disdain all talk of AGI safety (eg Facebook AI Research). Note that needing to solve AGI alignment only within a time limit, but with unlimited safe retries for rapid experimentation on the full-powered system; or only on the first critical try, but with an unlimited time bound; would both be terrifically humanity-threatening challenges by historical standards individually.”
I’m not sure if any of this fully resolves why AI safety people haven’t thought about slowing down AI more, or whether people should try to do it. But my sense is that many of the above reasons are at least somewhat wrong, and motives somewhat misguided, so I want to argue about a lot of them in turn, including both arguments and vague motivational themes.
The mundanity of the proposal
Restraint is not radical
There seems to be a common thought that technology is a kind of inevitable path along which the world must tread, and that trying to slow down or avoid any part of it would be both futile and extreme.2
But empirically, the world doesn’t pursue every technology—it barely pursues any technologies.
Sucky technologies
For a start, there are many machines that there is no pressure to make, because they have no value. Consider a machine that sprays shit in your eyes. We can technologically do that, but probably nobody has ever built that machine.
This might seem like a stupid example, because no serious ‘technology is inevitable’ conjecture is going to claim that totally pointless technologies are inevitable. But if you are sufficiently pessimistic about AI, I think this is the right comparison: if there are kinds of AI that would cause huge net costs to their creators if created, according to our best understanding, then they are at least as useless to make as the ‘spray shit in your eyes’ machine. We might accidentally make them due to error, but there is not some deep economic force pulling us to make them. If unaligned superintelligence destroys the world with high probability when you ask it to do a thing, then this is the category it is in, and it is not strange for its designs to just rot in the scrap-heap, with the machine that sprays shit in your eyes and the machine that spreads caviar on roads.
Ok, but maybe the relevant actors are very committed to being wrong about whether unaligned superintelligence would be a great thing to deploy. Or maybe you think the situation is less immediately dire and building existentially risky AI really would be good for the people making decisions (e.g. because the costs won’t arrive for a while, and the people care a lot about a shot at scientific success relative to a chunk of the future). If the apparent economic incentives are large, are technologies unavoidable?
Extremely valuable technologies
It doesn’t look like it to me. Here are a few technologies which I’d guess have substantial economic value, where research progress or uptake appears to be drastically slower than it could be, for reasons of concern about safety or ethics3:
It seems to me that intentionally slowing down progress in technologies to give time for even probably-excessive caution is commonplace. (And this is just looking at things slowed down over caution or ethics specifically—probably there are also other reasons things get slowed down.)
Furthermore, among valuable technologies that nobody is especially trying to slow down, it seems common enough for progress to be massively slowed by relatively minor obstacles, which is further evidence for a lack of overpowering strength of the economic forces at play. For instance, Fleming first took notice of mold’s effect on bacteria in 1928, but nobody took a serious, high-effort shot at developing it as a drug until 1939.4 Furthermore, in the thousands of years preceding these events, various people noticed numerous times that mold, other fungi or plants inhibited bacterial growth, but didn’t exploit this observation even enough for it not to be considered a new discovery in the 1920s. Meanwhile, people dying of infection was quite a thing. In 1930 about 300,000 Americans died of bacterial illnesses per year (around 250/100k).
My guess is that people make real choices about technology, and they do so in the face of economic forces that are feebler than commonly thought.
Restraint is not terrorism, usually
I think people have historically imagined weird things when they think of ‘slowing down AI’. I posit that their central image is sometimes terrorism (which understandably they don’t want to think about for very long), and sometimes some sort of implausibly utopian global agreement.
Here are some other things that ‘slow down AI capabilities’ could look like (where the best positioned person to carry out each one differs, but if you are not that person, you could e.g. talk to someone who is):
Coordination is not miraculous world government, usually
The common image of coordination seems to be explicit, centralized, involving of every party in the world, and something like cooperating on a prisoners’ dilemma: incentives push every rational party toward defection at all times, yet maybe through deontological virtues or sophisticated decision theories or strong international treaties, everyone manages to not defect for enough teetering moments to find another solution.
That is a possible way coordination could be. (And I think one that shouldn’t be seen as so hopeless—the world has actually coordinated on some impressive things, e.g. nuclear non-proliferation.) But if what you want is for lots of people to coincide in doing one thing when they might have done another, then there are quite a few ways of achieving that.
Consider some other case studies of coordinated behavior:
These are all cases of very broadscale coordination of behavior, none of which involve prisoners’ dilemma type situations, or people making explicit agreements which they then have an incentive to break. They do not involve centralized organization of huge multilateral agreements. Coordinated behavior can come from everyone individually wanting to make a certain choice for correlated reasons, or from people wanting to do things that those around them are doing, or from distributed behavioral dynamics such as punishment of violations, or from collaboration in thinking about a topic.
You might think they are weird examples that aren’t very related to AI. I think, a) it’s important to remember the plethora of weird dynamics that actually arise in human group behavior and not get carried away theorizing about AI in a world drained of everything but prisoners’ dilemmas and binding commitments, and b) the above are actually all potentially relevant dynamics here.
If AI in fact poses a large existential risk within our lifetimes, such that it is net bad for any particular individual, then the situation in theory looks a lot like that in the ‘avoiding eating sand’ case. It’s an option that a rational person wouldn’t want to take if they were just alone and not facing any kind of multi-agent situation. If AI is that dangerous, then not taking this inferior option could largely come from a coordination mechanism as simple as distribution of good information. (You still need to deal with irrational people and people with unusual values.)
But even failing coordinated caution from ubiquitous insight into the situation, other models might work. For instance, if there came to be somewhat widespread concern that AI research is bad, that might substantially lessen participation in it, beyond the set of people who are concerned, via mechanisms similar to those described above. Or it might give rise to a wide crop of local regulation, enforcing whatever behavior is deemed acceptable. Such regulation need not be centrally organized across the world to serve the purpose of coordinating the world, as long as it grew up in different places similarly. Which might happen because different locales have similar interests (all rational governments should be similarly concerned about losing power to automated power-seeking systems with unverifiable goals), or because—as with individuals—there are social dynamics which support norms arising in a non-centralized way.
The arms race model and its alternatives
Ok, maybe in principle you might hope to coordinate to not do self-destructive things, but realistically, if the US tries to slow down, won’t China or Facebook or someone less cautious take over the world?
Let’s be more careful about the game we are playing, game-theoretically speaking.
The arms race
What is an arms race, game theoretically? It’s an iterated prisoners’ dilemma, seems to me. Each round looks something like this:

Player 1 chooses a row, Player 2 chooses a column, and the resulting payoffs are listed in each cell, for {Player 1, Player 2} In this example, building weapons costs one unit. If anyone ends the round with more weapons than anyone else, they take all of their stuff (ten units).
In a single round of the game it’s always better to build weapons than not (assuming your actions are devoid of implications about your opponent’s actions). And it’s always better to get the hell out of this game.
This is not much like what the current AI situation looks like, if you think AI poses a substantial risk of destroying the world.
The suicide race
A closer model: as above except if anyone chooses to build, everything is destroyed (everyone loses all their stuff—ten units of value—as well as one unit if they built).

This is importantly different from the classic ‘arms race’ in that pressing the ‘everyone loses now’ button isn’t an equilibrium strategy.
That is: for anyone who thinks powerful misaligned AI represents near-certain death, the existence of other possible AI builders is not any reason to ‘race’.
But few people are that pessimistic. How about a milder version where there’s a good chance that the players ‘align the AI’?
The safety-or-suicide race
Ok, let’s do a game like the last but where if anyone builds, everything is only maybe destroyed (minus ten to all), and in the case of survival, everyone returns to the original arms race fun of redistributing stuff based on who built more than whom (+10 to a builder and -10 to a non-builder if there is one of each). So if you build AI alone, and get lucky on the probabilistic apocalypse, can still win big.
Let’s take 50% as the chance of doom if any building happens. Then we have a game whose expected payoffs are half way between those in the last two games:

(These are expected payoffs—the minus one unit return to building alone comes from the one unit cost of building, plus half a chance of losing ten in an extinction event and half a chance of taking ten from your opponent in a world takeover event.) Now you want to do whatever the other player is doing: build if they’ll build, pass if they’ll pass.
If the odds of destroying the world were very low, this would become the original arms race, and you’d always want to build. If very high, it would become the suicide race, and you’d never want to build. What the probabilities have to be in the real world to get you into something like these different phases is going to be different, because all these parameters are made up (the downside of human extinction is not 10x the research costs of building powerful AI, for instance).
But my point stands: even in terms of simplish models, it’s very non-obvious that we are in or near an arms race. And therefore, very non-obvious that racing to build advanced AI faster is even promising at a first pass.
In less game-theoretic terms: if you don’t seem anywhere near solving alignment, then racing as hard as you can to be the one who it falls upon to have solved alignment—especially if that means having less time to do so, though I haven’t discussed that here—is probably unstrategic. Having more ideologically pro-safety AI designers win an ‘arms race’ against less concerned teams is futile if you don’t have a way for such people to implement enough safety to actually not die, which seems like a very live possibility. (Robby Bensinger and maybe Andrew Critch somewhere make similar points.)
Conversations with my friends on this kind of topic can go like this:
Me: there’s no real incentive to race if the prize is mutual death
Them: sure, but it isn’t—if there’s a sliver of hope of surviving unaligned AI, and if your side taking control in that case is a bit better in expectation, and if they are going to build powerful AI anyway, then it’s worth racing. The whole future is on the line!
Me: Wouldn’t you still be better off directing your own efforts to safety, since your safety efforts will also help everyone end up with a safe AI?
Them: It will probably only help them somewhat—you don’t know if the other side will use your safety research. But also, it’s not just that they have less safety research. Their values are probably worse, by your lights.
Me: If they succeed at alignment, are foreign values really worse than local ones? Probably any humans with vast intelligence at hand have a similar shot at creating a glorious human-ish utopia, no?
Them: No, even if you’re right that being similarly human gets you to similar values in the end, the other parties might be more foolish than our side, and lock-in7 some poorly thought-through version of their values that they want at the moment, or even if all projects would be so foolish, our side might have better poorly thought-through values to lock in, as well as being more likely to use safety ideas at all. Even if racing is very likely to lead to death, and survival is very likely to lead to squandering most of the value, in that sliver of happy worlds so much is at stake in whether it is us or someone else doing the squandering!
Me: Hmm, seems complicated, I’m going to need paper for this.
The complicated race/anti-race
Here is a spreadsheet of models you can make a copy of and play with.
The first model is like this:
The second model is the same except that instead of dividing effort between safety and capabilities, you choose a speed, and the amount of alignment being done by each party is an exogenous parameter.
These models probably aren’t very good, but so far support a key claim I want to make here: it’s pretty non-obvious whether one should go faster or slower in this kind of scenario—it’s sensitive to a lot of different parameters in plausible ranges.
Furthermore, I don’t think the results of quantitative analysis match people’s intuitions here.
For example, here’s a situation which I think sounds intuitively like a you-should-race world, but where in the first model above, you should actually go as slowly as possible (this should be the one plugged into the spreadsheet now):
Your best bet here (on this model) is still to maximize safety investment. Why? Because by aggressively pursuing safety, you can get the other side half way to full safety, which is worth a lot more than than the lost chance of winning. Especially since if you ‘win’, you do so without much safety, and your victory without safety is worse than your opponent’s victory with safety, even if that too is far from perfect.
So if you are in a situation in this space, and the other party is racing, it’s not obvious if it is even in your narrow interests within the game to go faster at the expense of safety, though it may be.
These models are flawed in many ways, but I think they are better than the intuitive models that support arms-racing. My guess is that the next better still models remain nuanced.
Other equilibria and other games
Even if it would be in your interests to race if the other person were racing, ‘(do nothing, do nothing)’ is often an equilibrium too in these games. At least for various settings of the parameters. It doesn’t necessarily make sense to do nothing in the hope of getting to that equilibrium if you know your opponent to be mistaken about that and racing anyway, but in conjunction with communicating with your ‘opponent’, it seems like a theoretically good strategy.
This has all been assuming the structure of the game. I think the traditional response to an arms race situation is to remember that you are in a more elaborate world with all kinds of unmodeled affordances, and try to get out of the arms race.
Being friends with risk-takers
Caution is cooperative
Another big concern is that pushing for slower AI progress is ‘defecting’ against AI researchers who are friends of the AI safety community.
For instance Steven Byrnes:
“I think that trying to slow down research towards AGI through regulation would fail, because everyone (politicians, voters, lobbyists, business, etc.) likes scientific research and technological development, it creates jobs, it cures diseases, etc. etc., and you’re saying we should have less of that. So I think the effort would fail, and also be massively counterproductive by making the community of AI researchers see the community of AGI safety / alignment people as their enemies, morons, weirdos, Luddites, whatever.”
(Also a good example of the view criticized earlier, that regulation of things that create jobs and cure diseases just doesn’t happen.)
Or Eliezer Yudkowsky, on worry that spreading fear about AI would alienate top AI labs:
I don’t think this is a natural or reasonable way to see things, because:
It could be that people in control of AI capabilities would respond negatively to AI safety people pushing for slower progress. But that should be called ‘we might get punished’ not ‘we shouldn’t defect’. ‘Defection’ has moral connotations that are not due. Calling one side pushing for their preferred outcome ‘defection’ unfairly disempowers them by wrongly setting commonsense morality against them.
At least if it is the safety side. If any of the available actions are ‘defection’ that the world in general should condemn, I claim that it is probably ‘building machines that will plausibly destroy the world, or standing by while it happens’.
(This would be more complicated if the people involved were confident that they wouldn’t destroy the world and I merely disagreed with them. But about half of surveyed researchers are actually more pessimistic than me. And in a situation where the median AI researcher thinks the field has a 5-10% chance of causing human extinction, how confident can any responsible person be in their own judgment that it is safe?)
On top of all that, I worry that highlighting the narrative that wanting more cautious progress is defection is further destructive, because it makes it more likely that AI capabilities people see AI safety people as thinking of themselves as betraying AI researchers, if anyone engages in any such efforts. Which makes the efforts more aggressive. Like, if every time you see friends, you refer to it as ‘cheating on my partner’, your partner may reasonably feel hurt by your continual desire to see friends, even though the activity itself is innocuous.
‘We’ are not the US, ‘we’ are not the AI safety community
“If ‘we’ try to slow down AI, then the other side might win.” “If ‘we’ ask for regulation, then it might harm ‘our’ relationships with AI capabilities companies.” Who are these ‘we’s? Why are people strategizing for those groups in particular?
Even if slowing AI were uncooperative, and it were important for the AI Safety community to cooperate with the AI capabilities community, couldn’t one of the many people not in the AI Safety community work on it?
I have a longstanding irritation with thoughtless talk about what ‘we’ should do, without regard for what collective one is speaking for. So I may be too sensitive about it here. But I think confusions arising from this have genuine consequences.
I think when people say ‘we’ here, they generally imagine that they are strategizing on behalf of, a) the AI safety community, b) the USA, c) themselves or d) they and their readers. But those are a small subset of people, and not even obviously the ones the speaker can most influence (does the fact that you are sitting in the US really make the US more likely to listen to your advice than e.g. Estonia? Yeah probably on average, but not infinitely much.) If these naturally identified-with groups don’t have good options, that hardly means there are no options to be had, or to be communicated to other parties. Could the speaker speak to a different ‘we’? Maybe someone in the ‘we’ the speaker has in mind knows someone not in that group? If there is a strategy for anyone in the world, and you can talk, then there is probably a strategy for you.
The starkest appearance of error along these lines to me is in writing off the slowing of AI as inherently destructive of relations between the AI safety community and other AI researchers. If we grant that such activity would be seen as a betrayal (which seems unreasonable to me, but maybe), surely it could only be a betrayal if carried out by the AI safety community. There are quite a lot of people who aren’t in the AI safety community and have a stake in this, so maybe some of them could do something. It seems like a huge oversight to give up on all slowing of AI progress because you are only considering affordances available to the AI Safety Community.
Another example: if the world were in the basic arms race situation sometimes imagined, and the United States would be willing to make laws to mitigate AI risk, but could not because China would barge ahead, then that means China is in a great place to mitigate AI risk. Unlike the US, China could propose mutual slowing down, and the US would go along. Maybe it’s not impossible to communicate this to relevant people in China.
An oddity of this kind of discussion which feels related is the persistent assumption that one’s ability to act is restricted to the United States. Maybe I fail to understand the extent to which Asia is an alien and distant land where agency doesn’t apply, but for instance I just wrote to like a thousand machine learning researchers there, and maybe a hundred wrote back, and it was a lot like interacting with people in the US.
I’m pretty ignorant about what interventions will work in any particular country, including the US, but I just think it’s weird to come to the table assuming that you can essentially only affect things in one country. Especially if the situation is that you believe you have unique knowledge about what is in the interests of people in other countries. Like, fair enough I would be deal-breaker-level pessimistic if you wanted to get an Asian government to elect you leader or something. But if you think advanced AI is highly likely to destroy the world, including other countries, then the situation is totally different. If you are right, then everyone’s incentives are basically aligned.
I more weakly suspect some related mental shortcut is misshaping the discussion of arms races in general. The thought that something is a ‘race’ seems much stickier than alternatives, even if the true incentives don’t really make it a race. Like, against the laws of game theory, people sort of expect the enemy to try to believe falsehoods, because it will better contribute to their racing. And this feels like realism. The uncertain details of billions of people one barely knows about, with all manner of interests and relationships, just really wants to form itself into an ‘us’ and a ‘them’ in zero-sum battle. This is a mental shortcut that could really kill us.
My impression is that in practice, for many of the technologies slowed down for risk or ethics, mentioned in section ‘Extremely valuable technologies’ above, countries with fairly disparate cultures have converged on similar approaches to caution. I take this as evidence that none of ethical thought, social influence, political power, or rationality are actually very siloed by country, and in general the ‘countries in contest’ model of everything isn’t very good.
Notes on tractability
Convincing people doesn’t seem that hard
When I say that ‘coordination’ can just look like popular opinion punishing an activity, or that other countries don’t have much real incentive to build machines that will kill them, I think a common objection is that convincing people of the real situation is hopeless. The picture seems to be that the argument for AI risk is extremely sophisticated and only able to be appreciated by the most elite of intellectual elites—e.g. it’s hard enough to convince professors on Twitter, so surely the masses are beyond its reach, and foreign governments too.
This doesn’t match my overall experience on various fronts.
Some observations:
My weak guess is that immovable AI risk skeptics are concentrated in intellectual circles near the AI risk people, especially on Twitter, and that people with less of a horse in the intellectual status race are more readily like, ‘oh yeah, superintelligent robots are probably bad’. It’s not clear that most people even need convincing that there is a problem, though they don’t seem to consider it the most pressing problem in the world. (Though all of this may be different in cultures I am more distant from, e.g. in China.) I’m pretty non-confident about this, but skimming survey evidence suggests there is substantial though not overwhelming public concern about AI in the US8.
Do you need to convince everyone?
I could be wrong, but I’d guess convincing the ten most relevant leaders of AI labs that this is a massive deal, worth prioritizing, actually gets you a decent slow-down. I don’t have much evidence for this.
Buying time is big
You probably aren’t going to avoid AGI forever, and maybe huge efforts will buy you a couple of years.9 Could that even be worth it?
Seems pretty plausible:
It is also not obvious to me that these are the time-scales on the table. My sense is that things which are slowed down by regulation or general societal distaste are often slowed down much more than a year or two, and Eliezer’s stories presume that the world is full of collectives either trying to destroy the world or badly mistaken about it, which is not a foregone conclusion.
Delay is probably finite by default
While some people worry that any delay would be so short as to be negligible, others seem to fear that if AI research were halted, it would never start again and we would fail to go to space or something. This sounds so wild to me that I think I’m missing too much of the reasoning to usefully counterargue.
Obstruction doesn’t need discernment
Another purported risk of trying to slow things down is that it might involve getting regulators involved, and they might be fairly ignorant about the details of futuristic AI, and so tenaciously make the wrong regulations. Relatedly, if you call on the public to worry about this, they might have inexacting worries that call for impotent solutions and distract from the real disaster.
I don’t buy it. If all you want is to slow down a broad area of activity, my guess is that ignorant regulations do just fine at that every day (usually unintentionally). In particular, my impression is that if you mess up regulating things, a usual outcome is that many things are randomly slower than hoped. If you wanted to speed a specific thing up, that’s a very different story, and might require understanding the thing in question.
The same goes for social opposition. Nobody need understand the details of how genetic engineering works for its ascendancy to be seriously impaired by people not liking it. Maybe by their lights it still isn’t optimally undermined yet, but just not liking anything in the vicinity does go a long way.
This has nothing to do with regulation or social shaming specifically. You need to understand much less about a car or a country or a conversation to mess it up than to make it run well. It is a consequence of the general rule that there are many more ways for a thing to be dysfunctional than functional: destruction is easier than creation.
Back at the object level, I tentatively expect efforts to broadly slow down things in the vicinity of AI progress to slow down AI progress on net, even if poorly aimed.
Safety from speed, clout from complicity
Maybe it’s actually better for safety to have AI go fast at present, for various reasons. Notably:
And maybe it’s worth it to work on capabilities research at present, for instance because:
These all seem plausible. But also plausibly wrong. I don’t know of a decisive analysis of any of these considerations, and am not going to do one here. My impression is that they could basically all go either way.
I am actually particularly skeptical of the final argument, because if you believe what I take to be the normal argument for AI risk—that superhuman artificial agents won’t have acceptable values, and will aggressively manifest whatever values they do have, to the sooner or later annihilation of humanity—then the sentiments of the people turning on such machines seem like a very small factor, so long as they still turn the machines on. And I suspect that ‘having a person with my values doing X’ is commonly overrated. But the world is messier than these models, and I’d still pay a lot to be in the room to try.
Moods and philosophies, heuristics and attitudes
It’s not clear what role these psychological characters should play in a rational assessment of how to act, but I think they do play a role, so I want to argue about them.
Technological choice is not luddism
Some technologies are better than others [citation not needed]. The best pro-technology visions should disproportionately involve awesome technologies and avoid shitty technologies, I claim. If you think AGI is highly likely to destroy the world, then it is the pinnacle of shittiness as a technology. Being opposed to having it into your techno-utopia is about as luddite as refusing to have radioactive toothpaste there. Colloquially, Luddites are against progress if it comes as technology.10 Even if that’s a terrible position, its wise reversal is not the endorsement of all ‘technology’, regardless of whether it comes as progress.
Non-AGI visions of near-term thriving
Perhaps slowing down AI progress means foregoing our own generation’s hope for life-changing technologies. Some people thus find it psychologically difficult to aim for less AI progress (with its real personal costs), rather than shooting for the perhaps unlikely ‘safe AGI soon’ scenario.
I’m not sure that this is a real dilemma. The narrow AI progress we have seen already—i.e. further applications of current techniques at current scales—seems plausibly able to help a lot with longevity and other medicine for instance. And to the extent AI efforts could be focused on e.g. medically relevant narrow systems over creating agentic scheming gods, it doesn’t sound crazy to imagine making more progress on anti-aging etc as a result (even before taking into account the probability that the agentic scheming god does not prioritize your physical wellbeing as hoped). Others disagree with me here.
Robust priors vs. specific galaxy-brained models
There are things that are robustly good in the world, and things that are good on highly specific inside-view models and terrible if those models are wrong. Slowing dangerous tech development seems like the former, whereas forwarding arms races for dangerous tech between world superpowers seems more like the latter.11 There is a general question of how much to trust your reasoning and risk the galaxy-brained plan.12 But whatever your take on that, I think we should all agree that the less thought you have put into it, the more you should regress to the robustly good actions. Like, if it just occurred to you to take out a large loan to buy a fancy car, you probably shouldn’t do it because most of the time it’s a poor choice. Whereas if you have been thinking about it for a month, you might be sure enough that you are in the rare situation where it will pay off.
On this particular topic, it feels like people are going with the specific galaxy-brained inside-view terrible-if-wrong model off the bat, then not thinking about it more.
Cheems mindset/can’t do attitude
Suppose you have a friend, and you say ‘let’s go to the beach’ to them. Sometimes the friend is like ‘hell yes’ and then even if you don’t have towels or a mode of transport or time or a beach, you make it happen. Other times, even if you have all of those things, and your friend nominally wants to go to the beach, they will note that they have a package coming later, and that it might be windy, and their jacket needs washing. And when you solve those problems, they will note that it’s not that long until dinner time. You might infer that in the latter case your friend just doesn’t want to go to the beach. And sometimes that is the main thing going on! But I think there are also broader differences in attitudes: sometimes people are looking for ways to make things happen, and sometimes they are looking for reasons that they can’t happen. This is sometimes called a ‘cheems attitude’, or I like to call it (more accessibly) a ‘can’t do attitude’.
My experience in talking about slowing down AI with people is that they seem to have a can’t do attitude. They don’t want it to be a reasonable course: they want to write it off.
Which both seems suboptimal, and is strange in contrast with historical attitudes to more technical problem-solving. (As highlighted in my dialogue from the start of the post.)
It seems to me that if the same degree of can’t-do attitude were applied to technical safety, there would be no AI safety community because in 2005 Eliezer would have noticed any obstacles to alignment and given up and gone home.
To quote a friend on this, what would it look like if we *actually tried*?
Conclusion
This has been a miscellany of critiques against a pile of reasons I’ve met for not thinking about slowing down AI progress. I don’t think we’ve seen much reason here to be very pessimistic about slowing down AI, let alone reason for not even thinking about it.
I could go either way on whether any interventions to slow down AI in the near term are a good idea. My tentative guess is yes, but my main point here is just that we should think about it.
A lot of opinions on this subject seem to me to be poorly thought through, in error, and to have wrongly repelled the further thought that might rectify them. I hope to have helped a bit here by examining some such considerations enough to demonstrate that there are no good grounds for immediate dismissal. There are difficulties and questions, but if the same standards for ambition were applied here as elsewhere, I think we would see answers and action.
Acknowledgements
Thanks to Scott Alexander, Adam Scholl, Matthijs Maas, Joe Carlsmith, Ben Weinstein-Raun, Ronny Fernandez, Aysja Johnson, Jaan Tallinn, Rick Korzekwa, Owain Evans, Andrew Critch, Michael Vassar, Jessica Taylor, Rohin Shah, Jeffrey Heninger, Zach Stein-Perlman, Anthony Aguirre, Matthew Barnett, David Krueger, Harlan Stewart, Rafe Kennedy, Nick Beckstead, Leopold Aschenbrenner, Michaël Trazzi, Oliver Habryka, Shahar Avin, Luke Muehlhauser, Michael Nielsen, Nathan Young and quite a few others for discussion and/or encouragement.
Notes
1 I haven’t heard this in recent times, so maybe views have changed. An example of earlier times: Nick Beckstead, 2015: “One idea we sometimes hear is that it would be harmful to speed up the development of artificial intelligence because not enough work has been done to ensure that when very advanced artificial intelligence is created, it will be safe. This problem, it is argued, would be even worse if progress in the field accelerated. However, very advanced artificial intelligence could be a useful tool for overcoming other potential global catastrophic risks. If it comes sooner—and the world manages to avoid the risks that it poses directly—the world will spend less time at risk from these other factors….
I found that speeding up advanced artificial intelligence—according to my simple interpretation of these survey results—could easily result in reduced net exposure to the most extreme global catastrophic risks…”2 This is closely related to Bostrom’s Technological completion conjecture: “If scientific and technological development efforts do not effectively cease, then all important basic capabilities that could be obtained through some possible technology will be obtained.” (Bostrom, Superintelligence, pp. 228, Chapter 14, 2014)
Bostrom illustrates this kind of position (though apparently rejects it; from Superintelligence, found here): “Suppose that a policymaker proposes to cut funding for a certain research field, out of concern for the risks or long-term consequences of some hypothetical technology that might eventually grow from its soil. She can then expect a howl of opposition from the research community. Scientists and their public advocates often say that it is futile to try to control the evolution of technology by blocking research. If some technology is feasible (the argument goes) it will be developed regardless of any particular policymaker’s scruples about speculative future risks. Indeed, the more powerful the capabilities that a line of development promises to produce, the surer we can be that somebody, somewhere, will be motivated to pursue it. Funding cuts will not stop progress or forestall its concomitant dangers.”
This kind of thing is also discussed by Dafoe and Sundaram, Maas & Beard3 (Some inspiration from Matthijs Maas’ spreadsheet, from Paths Untaken, and from GPT-3.)
4 From a private conversation with Rick Korzekwa, who may have read https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1139110/ and an internal draft at AI Impacts, probably forthcoming.
5 More here and here. I haven’t read any of these, but it’s been a topic of discussion for a while.
6 “To aid in promoting secrecy, schemes to improve incentives were devised. One method sometimes used was for authors to send papers to journals to establish their claim to the finding but ask that publication of the papers be delayed indefinitely.26,27,28,29 Szilárd also suggested offering funding in place of credit in the short term for scientists willing to submit to secrecy and organizing limited circulation of key papers.30” – Me, previously
7 ‘Lock-in’ of values is the act of using powerful technology such as AI to ensure that specific values will stably control the future.
8 And also in Britain:
‘This paper discusses the results of a nationally representative survey of the UK population on their perceptions of AI…the most common visions of the impact of AI elicit significant anxiety. Only two of the eight narratives elicited more excitement than concern (AI making life easier, and extending life). Respondents felt they had no control over AI’s development, citing the power of corporations or government, or versions of technological determinism. Negotiating the deployment of AI will require contending with these anxieties.’9 Or so worries Eliezer Yudkowsky—
In MIRI announces new “Death With Dignity” strategy:In AGI Ruin: A List of Lethalities:
10 I’d guess real Luddites also thought the technological changes they faced were anti-progress, but in that case were they wrong to want to avoid them?
11 I hear this is an elaboration on this theme, but I haven’t read it.
12 Leopold Aschenbrenner partly defines ‘Burkean Longtermism’ thus: “We should be skeptical of any radical inside-view schemes to positively steer the long-run future, given the froth of uncertainty about the consequences of our actions.”
- I take ‘slowing down dangerous AI’ to include any of:
-
Counterarguments to the basic AI risk case
Crossposted from The AI Impacts blog.
This is going to be a list of holes I see in the basic argument for existential risk from superhuman AI systems1.
To start, here’s an outline of what I take to be the basic case2:
I. If superhuman AI systems are built, any given system is likely to be ‘goal-directed’
Reasons to expect this:
- Goal-directed behavior is likely to be valuable, e.g. economically.
- Goal-directed entities may tend to arise from machine learning training processes not intending to create them (at least via the methods that are likely to be used).
- ‘Coherence arguments’ may imply that systems with some goal-directedness will become more strongly goal-directed over time.
II. If goal-directed superhuman AI systems are built, their desired outcomes will probably be about as bad as an empty universe by human lights
Reasons to expect this:
- Finding useful goals that aren’t extinction-level bad appears to be hard: we don’t have a way to usefully point at human goals, and divergences from human goals seem likely to produce goals that are in intense conflict with human goals, due to a) most goals producing convergent incentives for controlling everything, and b) value being ‘fragile’, such that an entity with ‘similar’ values will generally create a future of virtually no value.
- Finding goals that are extinction-level bad and temporarily useful appears to be easy: for example, advanced AI with the sole objective ‘maximize company revenue’ might profit said company for a time before gathering the influence and wherewithal to pursue the goal in ways that blatantly harm society.
- Even if humanity found acceptable goals, giving a powerful AI system any specific goals appears to be hard. We don’t know of any procedure to do it, and we have theoretical reasons to expect that AI systems produced through machine learning training will generally end up with goals other than those they were trained according to. Randomly aberrant goals resulting are probably extinction-level bad for reasons described in II.1 above.
III. If most goal-directed superhuman AI systems have bad goals, the future will very likely be bad
That is, a set of ill-motivated goal-directed superhuman AI systems, of a scale likely to occur, would be capable of taking control over the future from humans. This is supported by at least one of the following being true:
- Superhuman AI would destroy humanity rapidly. This may be via ultra-powerful capabilities at e.g. technology design and strategic scheming, or through gaining such powers in an ‘intelligence explosion‘ (self-improvement cycle). Either of those things may happen either through exceptional heights of intelligence being reached or through highly destructive ideas being available to minds only mildly beyond our own.
- Superhuman AI would gradually come to control the future via accruing power and resources. Power and resources would be more available to the AI system(s) than to humans on average, because of the AI having far greater intelligence.
Below is a list of gaps in the above, as I see it, and counterarguments. A ‘gap’ is not necessarily unfillable, and may have been filled in any of the countless writings on this topic that I haven’t read. I might even think that a given one can probably be filled. I just don’t know what goes in it.
This blog post is an attempt to run various arguments by you all on the way to making pages on AI Impacts about arguments for AI risk and corresponding counterarguments. At some point in that process I hope to also read others’ arguments, but this is not that day. So what you have here is a bunch of arguments that occur to me, not an exhaustive literature review.
Counterarguments
A. Contra “superhuman AI systems will be ‘goal-directed’”
Different calls to ‘goal-directedness’ don’t necessarily mean the same concept
‘Goal-directedness’ is a vague concept. It is unclear that the ‘goal-directednesses’ that are favored by economic pressure, training dynamics or coherence arguments (the component arguments in part I of the argument above) are the same ‘goal-directedness’ that implies a zealous drive to control the universe (i.e. that makes most possible goals very bad, fulfilling II above).
One well-defined concept of goal-directedness is ‘utility maximization’: always doing what maximizes a particular utility function, given a particular set of beliefs about the world.
Utility maximization does seem to quickly engender an interest in controlling literally everything, at least for many utility functions one might have3. If you want things to go a certain way, then you have reason to control anything which gives you any leverage over that, i.e. potentially all resources in the universe (i.e. agents have ‘convergent instrumental goals’). This is in serious conflict with anyone else with resource-sensitive goals, even if prima facie those goals didn’t look particularly opposed. For instance, a person who wants all things to be red and another person who wants all things to be cubes may not seem to be at odds, given that all things could be red cubes. However if these projects might each fail for lack of energy, then they are probably at odds.
Thus utility maximization is a notion of goal-directedness that allows Part II of the argument to work, by making a large class of goals deadly.
You might think that any other concept of ‘goal-directedness’ would also lead to this zealotry. If one is inclined toward outcome O in any plausible sense, then does one not have an interest in anything that might help procure O? No: if a system is not a ‘coherent’ agent, then it can have a tendency to bring about O in a range of circumstances, without this implying that it will take any given effective opportunity to pursue O. This assumption of consistent adherence to a particular evaluation of everything is part of utility maximization, not a law of physical systems. Call machines that push toward particular goals but are not utility maximizers pseudo-agents.
Can pseudo-agents exist? Yes—utility maximization is computationally intractable, so any physically existent ‘goal-directed’ entity is going to be a pseudo-agent. We are all pseudo-agents, at best. But it seems something like a spectrum. At one end is a thermostat, then maybe a thermostat with a better algorithm for adjusting the heat. Then maybe a thermostat which intelligently controls the windows. After a lot of honing, you might have a system much more like a utility-maximizer: a system that deftly seeks out and seizes well-priced opportunities to make your room 68 degrees—upgrading your house, buying R&D, influencing your culture, building a vast mining empire. Humans might not be very far on this spectrum, but they seem enough like utility-maximizers already to be alarming. (And it might not be well-considered as a one-dimensional spectrum—for instance, perhaps ‘tendency to modify oneself to become more coherent’ is a fairly different axis from ‘consistency of evaluations of options and outcomes’, and calling both ‘more agentic’ is obscuring.)
Nonetheless, it seems plausible that there is a large space of systems which strongly increase the chance of some desirable objective O occurring without even acting as much like maximizers of an identifiable utility function as humans would. For instance, without searching out novel ways of making O occur, or modifying themselves to be more consistently O-maximizing. Call these ‘weak pseudo-agents’.
For example, I can imagine a system constructed out of a huge number of ‘IF X THEN Y’ statements (reflexive responses), like ‘if body is in hallway, move North’, ‘if hands are by legs and body is in kitchen, raise hands to waist’.., equivalent to a kind of vector field of motions, such that for every particular state, there are directions that all the parts of you should be moving. I could imagine this being designed to fairly consistently cause O to happen within some context. However since such behavior would not be produced by a process optimizing O, you shouldn’t expect it to find new and strange routes to O, or to seek O reliably in novel circumstances. There appears to be zero pressure for this thing to become more coherent, unless its design already involves reflexes to move its thoughts in certain ways that lead it to change itself. I expect you could build a system like this that reliably runs around and tidies your house say, or runs your social media presence, without it containing any impetus to become a more coherent agent (because it doesn’t have any reflexes that lead to pondering self-improvement in this way).
It is not clear that economic incentives generally favor the far end of this spectrum over weak pseudo-agency. There are incentives toward systems being more like utility maximizers, but also incentives against.
The reason any kind of ‘goal-directedness’ is incentivised in AI systems is that then the system can be given an objective by someone hoping to use their cognitive labor, and the system will make that objective happen. Whereas a similar non-agentic AI system might still do almost the same cognitive labor, but require an agent (such as a person) to look at the objective and decide what should be done to achieve it, then ask the system for that. Goal-directedness means automating this high-level strategizing.
Weak pseudo-agency fulfills this purpose to some extent, but not as well as utility maximization. However if we think that utility maximization is difficult to wield without great destruction, then that suggests a disincentive to creating systems with behavior closer to utility-maximization. Not just from the world being destroyed, but from the same dynamic causing more minor divergences from expectations, if the user can’t specify their own utility function well.
That is, if it is true that utility maximization tends to lead to very bad outcomes relative to any slightly different goals (in the absence of great advances in the field of AI alignment), then the most economically favored level of goal-directedness seems unlikely to be as far as possible toward utility maximization. More likely it is a level of pseudo-agency that achieves a lot of the users’ desires without bringing about sufficiently detrimental side effects to make it not worthwhile. (This is likely more agency than is socially optimal, since some of the side-effects will be harms to others, but there seems no reason to think that it is a very high degree of agency.)
Some minor but perhaps illustrative evidence: anecdotally, people prefer interacting with others who predictably carry out their roles or adhere to deontological constraints, rather than consequentialists in pursuit of broadly good but somewhat unknown goals. For instance, employers would often prefer employees who predictably follow rules than ones who try to forward company success in unforeseen ways.
The other arguments to expect goal-directed systems mentioned above seem more likely to suggest approximate utility-maximization rather than some other form of goal-directedness, but it isn’t that clear to me. I don’t know what kind of entity is most naturally produced by contemporary ML training. Perhaps someone else does. I would guess that it’s more like the reflex-based agent described above, at least at present. But present systems aren’t the concern.
Coherence arguments are arguments for being coherent a.k.a. maximizing a utility function, so one might think that they imply a force for utility maximization in particular. That seems broadly right. Though note that these are arguments that there is some pressure for the system to modify itself to become more coherent. What actually results from specific systems modifying themselves seems like it might have details not foreseen in an abstract argument merely suggesting that the status quo is suboptimal whenever it is not coherent. Starting from a state of arbitrary incoherence and moving iteratively in one of many pro-coherence directions produced by whatever whacky mind you currently have isn’t obviously guaranteed to increasingly approximate maximization of some sensical utility function. For instance, take an entity with a cycle of preferences, apples > bananas = oranges > pears > apples. The entity notices that it sometimes treats oranges as better than pears and sometimes worse. It tries to correct by adjusting the value of oranges to be the same as pears. The new utility function is exactly as incoherent as the old one. Probably moves like this are rarer than ones that make you more coherent in this situation, but I don’t know, and I also don’t know if this is a great model of the situation for incoherent systems that could become more coherent.
What it might look like if this gap matters: AI systems proliferate, and have various goals. Some AI systems try to make money in the stock market. Some make movies. Some try to direct traffic optimally. Some try to make the Democratic party win an election. Some try to make Walmart maximally profitable. These systems have no perceptible desire to optimize the universe for forwarding these goals because they aren’t maximizing a general utility function, they are more ‘behaving like someone who is trying to make Walmart profitable’. They make strategic plans and think about their comparative advantage and forecast business dynamics, but they don’t build nanotechnology to manipulate everybody’s brains, because that’s not the kind of behavior pattern they were designed to follow. The world looks kind of like the current world, in that it is fairly non-obvious what any entity’s ‘utility function’ is. It often looks like AI systems are ‘trying’ to do things, but there’s no reason to think that they are enacting a rational and consistent plan, and they rarely do anything shocking or galaxy-brained.
Ambiguously strong forces for goal-directedness need to meet an ambiguously high bar to cause a risk
The forces for goal-directedness mentioned in I are presumably of finite strength. For instance, if coherence arguments correspond to pressure for machines to become more like utility maximizers, there is an empirical answer to how fast that would happen with a given system. There is also an empirical answer to how ‘much’ goal directedness is needed to bring about disaster, supposing that utility maximization would bring about disaster and, say, being a rock wouldn’t. Without investigating these empirical details, it is unclear whether a particular qualitatively identified force for goal-directedness will cause disaster within a particular time.
What it might look like if this gap matters: There are not that many systems doing something like utility maximization in the new AI economy. Demand is mostly for systems more like GPT or DALL-E, which transform inputs in some known way without reference to the world, rather than ‘trying’ to bring about an outcome. Maybe the world was headed for more of the latter, but ethical and safety concerns reduced desire for it, and it wasn’t that hard to do something else. Companies setting out to make non-agentic AI systems have no trouble doing so. Incoherent AIs are never observed making themselves more coherent, and training has never produced an agent unexpectedly. There are lots of vaguely agentic things, but they don’t pose much of a problem. There are a few things at least as agentic as humans, but they are a small part of the economy.
B. Contra “goal-directed AI systems’ goals will be bad”
Small differences in utility functions may not be catastrophic
Arguably, humans are likely to have somewhat different values to one another even after arbitrary reflection. If so, there is some extended region of the space of possible values that the values of different humans fall within. That is, ‘human values’ is not a single point.
If the values of misaligned AI systems fall within that region, this would not appear to be worse in expectation than the situation where the long-run future was determined by the values of humans other than you. (This may still be a huge loss of value relative to the alternative, if a future determined by your own values is vastly better than that chosen by a different human, and if you also expected to get some small fraction of the future, and will now get much less. These conditions seem non-obvious however, and if they obtain you should worry about more general problems than AI.)
Plausibly even a single human, after reflecting, could on their own come to different places in a whole region of specific values, depending on somewhat arbitrary features of how the reflecting period went. In that case, even the values-on-reflection of a single human is an extended region of values space, and an AI which is only slightly misaligned could be the same as some version of you after reflecting.
There is a further larger region, ‘that which can be reliably enough aligned with typical human values via incentives in the environment’, which is arguably larger than the circle containing most human values. Human society makes use of this a lot: for instance, most of the time particularly evil humans don’t do anything too objectionable because it isn’t in their interests. This region is probably smaller for more capable creatures such as advanced AIs, but still it is some size.
Thus it seems that some amount4 of AI divergence from your own values is probably broadly fine, i.e. not worse than what you should otherwise expect without AI.
Thus in order to arrive at a conclusion of doom, it is not enough to argue that we cannot align AI perfectly. The question is a quantitative one of whether we can get it close enough. And how close is ‘close enough’ is not known.
What it might look like if this gap matters: there are many superintelligent goal-directed AI systems around. They are trained to have human-like goals, but we know that their training is imperfect and none of them has goals exactly like those presented in training. However if you just heard about a particular system’s intentions, you wouldn’t be able to guess if it was an AI or a human. Things happen much faster than they were, because superintelligent AI is superintelligent, but not obviously in a direction less broadly in line with human goals than when humans were in charge.
Differences between AI and human values may be small
AI trained to have human-like goals will have something close to human-like goals. How close? Call it d, for a particular occasion of training AI.
If d doesn’t have to be 0 for safety (from above), then there is a question of whether it is an acceptable size.
I know of two issues here, pushing d upward. One is that with a finite number of training examples, the fit between the true function and the learned function will be wrong. The other is that you might accidentally create a monster (‘misaligned mesaoptimizer’) who understands its situation and pretends to have the utility function you are aiming for so that it can be freed and go out and manifest its own utility function, which could be just about anything. If this problem is real, then the values of an AI system might be arbitrarily different from the training values, rather than ‘nearby’ in some sense, so d is probably unacceptably large. But if you avoid creating such mesaoptimizers, then it seems plausible to me that d is very small.
If humans also substantially learn their values via observing examples, then the variation in human values is arising from a similar process, so might be expected to be of a similar scale. If we care to make the ML training process more accurate than the human learning one, it seems likely that we could. For instance, d gets smaller with more data.
Another line of evidence is that for things that I have seen AI learn so far, the distance from the real thing is intuitively small. If AI learns my values as well as it learns what faces look like, it seems plausible that it carries them out better than I do.
As minor additional evidence here, I don’t know how to describe any slight differences in utility functions that are catastrophic. Talking concretely, what does a utility function look like that is so close to a human utility function that an AI system has it after a bunch of training, but which is an absolute disaster? Are we talking about the scenario where the AI values a slightly different concept of justice, or values satisfaction a smidgen more relative to joy than it should? And then that’s a moral disaster because it is wrought across the cosmos? Or is it that it looks at all of our inaction and thinks we want stuff to be maintained very similar to how it is now, so crushes any efforts to improve things?
What it might look like if this gap matters: when we try to train AI systems to care about what specific humans care about, they usually pretty much do, as far as we can tell. We basically get what we trained for. For instance, it is hard to distinguish them from the human in question. (It is still important to actually do this training, rather than making AI systems not trained to have human values.)
Maybe value isn’t fragile
Eliezer argued that value is fragile, via examples of ‘just one thing’ that you can leave out of a utility function, and end up with something very far away from what humans want. For instance, if you leave out ‘boredom’ then he thinks the preferred future might look like repeating the same otherwise perfect moment again and again. (His argument is perhaps longer—that post says there is a lot of important background, though the bits mentioned don’t sound relevant to my disagreement.) This sounds to me like ‘value is not resilient to having components of it moved to zero’, which is a weird usage of ‘fragile’, and in particular, doesn’t seem to imply much about smaller perturbations. And smaller perturbations seem like the relevant thing with AI systems trained on a bunch of data to mimic something.
You could very analogously say ‘human faces are fragile’ because if you just leave out the nose it suddenly doesn’t look like a typical human face at all. Sure, but is that the kind of error you get when you try to train ML systems to mimic human faces? Almost none of the faces on thispersondoesnotexist.com are blatantly morphologically unusual in any way, let alone noseless. Admittedly one time I saw someone whose face was neon green goo, but I’m guessing you can get the rate of that down pretty low if you care about it.
Eight examples, no cherry-picking:
Skipping the nose is the kind of mistake you make if you are a child drawing a face from memory. Skipping ‘boredom’ is the kind of mistake you make if you are a person trying to write down human values from memory. My guess is that this seemed closer to the plan in 2009 when that post was written, and that people cached the takeaway and haven’t updated it for deep learning which can learn what faces look like better than you can.
What it might look like if this gap matters: there is a large region ‘around’ my values in value space that is also pretty good according to me. AI easily lands within that space, and eventually creates some world that is about as good as the best possible utopia, according to me. There aren’t a lot of really crazy and terrible value systems adjacent to my values.
Short-term goals
Utility maximization really only incentivises drastically altering the universe if one’s utility function places a high enough value on very temporally distant outcomes relative to near ones. That is, long term goals are needed for danger. A person who cares most about winning the timed chess game in front of them should not spend time accruing resources to invest in better chess-playing.
AI systems could have long-term goals via people intentionally training them to do so, or via long-term goals naturally arising from systems not trained so.
Humans seem to discount the future a lot in their usual decision-making (they have goals years in advance but rarely a hundred years) so the economic incentive to train AI to have very long term goals might be limited.
It’s not clear that training for relatively short term goals naturally produces creatures with very long term goals, though it might.
Thus if AI systems fail to have value systems relatively similar to human values, it is not clear that many will have the long time horizons needed to motivate taking over the universe.
What it might look like if this gap matters: the world is full of agents who care about relatively near-term issues, and are helpful to that end, and have no incentive to make long-term large scale schemes. Reminiscent of the current world, but with cleverer short-termism.
C. Contra “superhuman AI would be sufficiently superior to humans to overpower humanity”
Human success isn’t from individual intelligence
The argument claims (or assumes) that surpassing ‘human-level’ intelligence (i.e. the mental capacities of an individual human) is the relevant bar for matching the power-gaining capacity of humans, such that passing this bar in individual intellect means outcompeting humans in general in terms of power (argument III.2), if not being able to immediately destroy them all outright (argument III.1.). In a similar vein, introductions to AI risk often start by saying that humanity has triumphed over the other species because it is more intelligent, as a lead in to saying that if we make something more intelligent still, it will inexorably triumph over humanity.
This hypothesis about the provenance of human triumph seems wrong. Intellect surely helps, but humans look to be powerful largely because they share their meager intellectual discoveries with one another and consequently save them up over time5. You can see this starkly by comparing the material situation of Alice, a genius living in the stone age, and Bob, an average person living in 21st Century America. Alice might struggle all day to get a pot of water, while Bob might be able to summon all manner of delicious drinks from across the oceans, along with furniture, electronics, information, etc. Much of Bob’s power probably did flow from the application of intelligence, but not Bob’s individual intelligence. Alice’s intelligence, and that of those who came between them.
Bob’s greater power isn’t directly just from the knowledge and artifacts Bob inherits from other humans. He also seems to be helped for instance by much better coordination: both from a larger number people coordinating together, and from better infrastructure for that coordination (e.g. for Alice the height of coordination might be an occasional big multi-tribe meeting with trade, and for Bob it includes global instant messaging and banking systems and the Internet). One might attribute all of this ultimately to innovation, and thus to intelligence and communication, or not. I think it’s not important to sort out here, as long as it’s clear that individual intelligence isn’t the source of power.
It could still be that with a given bounty of shared knowledge (e.g. within a given society), intelligence grants huge advantages. But even that doesn’t look true here: 21st Century geniuses live basically like 21st Century people of average intelligence, give or take6.
Why does this matter? Well for one thing, if you make AI which is merely as smart as a human, you shouldn’t then expect it to do that much better than a genius living in the stone age. That’s what human-level intelligence gets you: nearly nothing. A piece of rope after millions of lifetimes. Humans without their culture are much like other animals.
To wield the control-over-the-world of a genius living in the 21st Century, the human-level AI would seem to need something like the other benefits that the 21st century genius gets from their situation in connection with a society.
One such thing is access to humanity’s shared stock of hard-won information. AI systems plausibly do have this, if they can get most of what is relevant by reading the internet. This isn’t obvious: people also inherit information from society through copying habits and customs, learning directly from other people, and receiving artifacts with implicit information (for instance, a factory allows whoever owns the factory to make use of intellectual work that was done by the people who built the factory, but that information may not available explicitly even for the owner of the factory, let alone to readers on the internet). These sources of information seem likely to also be available to AI systems though, at least if they are afforded the same options as humans.
My best guess is that AI systems easily do better than humans on extracting information from humanity’s stockpile, and on coordinating, and so on this account are probably in an even better position to compete with humans than one might think on the individual intelligence model, but that is a guess. In that case perhaps this misunderstanding makes little difference to the outcomes of the argument. However it seems at least a bit more complicated.
Suppose that AI systems can have access to all information humans can have access to. The power the 21st century person gains from their society is modulated by their role in society, and relationships, and rights, and the affordances society allows them as a result. Their power will vary enormously depending on whether they are employed, or listened to, or paid, or a citizen, or the president. If AI systems’ power stems substantially from interacting with society, then their power will also depend on affordances granted, and humans may choose not to grant them many affordances (see section ‘Intelligence may not be an overwhelming advantage’ for more discussion).
However suppose that your new genius AI system is also treated with all privilege. The next way that this alternate model matters is that if most of what is good in a person’s life is determined by the society they are part of, and their own labor is just buying them a tiny piece of that inheritance, then if they are for instance twice as smart as any other human, they don’t get to use technology that it twice as good. They just get a larger piece of that same shared technological bounty purchasable by anyone. Because each individual person is adding essentially nothing in terms of technology, so twice that is still basically nothing.
In contrast, I think people are often imagining that a single entity somewhat smarter than a human will be able to quickly use technologies that are somewhat better than current human technologies. This seems to be mistaking the actions of a human and the actions of a human society. If a hundred thousand people sometimes get together for a few years and make fantastic new weapons, you should not expect an entity somewhat smarter than a person to make even better weapons. That’s off by a factor of about a hundred thousand.
There might be places you can get far ahead of humanity by being better than a single human—it depends how much accomplishments depend on the few most capable humans in the field, and how few people are working on the problem7. But for instance the Manhattan Project took a hundred thousand people several years, and von Neumann (a mythically smart scientist) joining the project did not reduce it to an afternoon. Plausibly to me, some specific people being on the project caused it to not take twice as many person-years, though the plausible candidates here seem to be more in the business of running things than doing science directly (though that also presumably involves intelligence). But even if you are an ambitious somewhat superhuman intelligence, the influence available to you seems to plausibly be limited to making a large dent in the effort required for some particular research endeavor, not single-handedly outmoding humans across many research endeavors.
This is all reason to doubt that a small number of superhuman intelligences will rapidly take over or destroy the world (as in III.i.). This doesn’t preclude a set of AI systems that are together more capable than a large number of people from making great progress. However some related issues seem to make that less likely.
Another implication of this model is that if most human power comes from buying access to society’s shared power, i.e. interacting with the economy, you should expect intellectual labor by AI systems to usually be sold, rather than for instance put toward a private stock of knowledge. This means the intellectual outputs are mostly going to society, and the main source of potential power to an AI system is the wages received (which may allow it to gain power in the long run). However it seems quite plausible that AI systems at this stage will generally not receive wages, since they presumably do not need them to be motivated to do the work they were trained for. It also seems plausible that they would be owned and run by humans. This would seem to not involve any transfer of power to that AI system, except insofar as its intellectual outputs benefit it (e.g. if it is writing advertising material, maybe it doesn’t get paid for that, but if it can write material that slightly furthers its own goals in the world while also fulfilling the advertising requirements, then it sneaked in some influence.)
If there is AI which is moderately more competent than humans, but not sufficiently more competent to take over the world, then it is likely to contribute to this stock of knowledge and affordances shared with humans. There is no reason to expect it to build a separate competing stock, any more than there is reason for a current human household to try to build a separate competing stock rather than sell their labor to others in the economy.
In summary:
- Functional connection with a large community of other intelligences in the past and present is probably a much bigger factor in the success of humans as a species or individual humans than is individual intelligence.
- Thus this also seems more likely to be important for AI success than individual intelligence. This is contrary to a usual argument for AI superiority, but probably leaves AI systems at least as likely to outperform humans, since superhuman AI is probably superhumanly good at taking in information and coordinating.
- However it is not obvious that AI systems will have the same access to society’s accumulated information e.g. if there is information which humans learn from living in society, rather than from reading the internet.
- And it seems an open question whether AI systems are given the same affordances in society as humans, which also seem important to making use of the accrued bounty of power over the world that humans have. For instance, if they are not granted the same legal rights as humans, they may be at a disadvantage in doing trade or engaging in politics or accruing power.
- The fruits of greater intelligence for an entity will probably not look like society-level accomplishments unless it is a society-scale entity
- The route to influence with smaller fruits probably by default looks like participating in the economy rather than trying to build a private stock of knowledge.
- If the resources from participating in the economy accrue to the owners of AI systems, not to the systems themselves, then there is less reason to expect the systems to accrue power incrementally, and they are at a severe disadvantage relative to humans.
Overall these are reasons to expect AI systems with around human-level cognitive performance to not destroy the world immediately, and to not amass power as easily as one might imagine.
What it might look like if this gap matters: If AI systems are somewhat superhuman, then they do impressive cognitive work, and each contributes to technology more than the best human geniuses, but not more than the whole of society, and not enough to materially improve their own affordances. They don’t gain power rapidly because they are disadvantaged in other ways, e.g. by lack of information, lack of rights, lack of access to positions of power. Their work is sold and used by many actors, and the proceeds go to their human owners. AI systems do not generally end up with access to masses of technology that others do not have access to, and nor do they have private fortunes. In the long run, as they become more powerful, they might take power if other aspects of the situation don’t change.
AI agents may not be radically superior to combinations of humans and non-agentic machines
‘Human level capability’ is a moving target. For comparing the competence of advanced AI systems to humans, the relevant comparison is with humans who have state-of-the-art AI and other tools. For instance, the human capacity to make art quickly has recently been improved by a variety of AI art systems. If there were now an agentic AI system that made art, it would make art much faster than a human of 2015, but perhaps hardly faster than a human of late 2022. If humans continually have access to tool versions of AI capabilities, it is not clear that agentic AI systems must ever have an overwhelmingly large capability advantage for important tasks (though they might).
(This is not an argument that humans might be better than AI systems, but rather: if the gap in capability is smaller, then the pressure for AI systems to accrue power is less and thus loss of human control is slower and easier to mitigate entirely through other forces, such as subsidizing human involvement or disadvantaging AI systems in the economy.)
Some advantages of being an agentic AI system vs. a human with a tool AI system seem to be:
- There might just not be an equivalent tool system, for instance if it is impossible to train systems without producing emergent agents.
- When every part of a process takes into account the final goal, this should make the choices within the task more apt for the final goal (and agents know their final goal, whereas tools carrying out parts of a larger problem do not).
- For humans, the interface for using a capability of one’s mind tends to be smoother than the interface for using a tool. For instance a person who can do fast mental multiplication can do this more smoothly and use it more often than a person who needs to get out a calculator. This seems likely to persist.
1 and 2 may or may not matter much. 3 matters more for brief, fast, unimportant tasks. For instance, consider again people who can do mental calculations better than others. My guess is that this advantages them at using Fermi estimates in their lives and buying cheaper groceries, but does not make them materially better at making large financial choices well. For a one-off large financial choice, the effort of getting out a calculator is worth it and the delay is very short compared to the length of the activity. The same seems likely true of humans with tools vs. agentic AI with the same capacities integrated into their minds. Conceivably the gap between humans with tools and goal-directed AI is small for large, important tasks.
What it might look like if this gap matters: agentic AI systems have substantial advantages over humans with tools at some tasks like rapid interaction with humans, and responding to rapidly evolving strategic situations. One-off large important tasks such as advanced science are mostly done by tool AI.
Trust
If goal-directed AI systems are only mildly more competent than some combination of tool systems and humans (as suggested by considerations in the last two sections), we still might expect AI systems to out-compete humans, just more slowly. However AI systems have one serious disadvantage as employees of humans: they are intrinsically untrustworthy, while we don’t understand them well enough to be clear on what their values are or how they will behave in any given case. Even if they did perform as well as humans at some task, if humans can’t be certain of that, then there is reason to disprefer using them. This can be thought of as two problems: firstly, slightly misaligned systems are less valuable because they genuinely do the thing you want less well, and secondly, even if they were not misaligned, if humans can’t know that (because we have no good way to verify the alignment of AI systems) then it is costly in expectation to use them. (This is only a further force acting against the supremacy of AI systems—they might still be powerful enough that using them is enough of an advantage that it is worth taking the hit on trustworthiness.)
What it might look like if this gap matters: in places where goal-directed AI systems are not typically hugely better than some combination of less goal-directed systems and humans, the job is often given to the latter if trustworthiness matters.
Headroom
For AI to vastly surpass human performance at a task, there needs to be ample room for improvement above human level. For some tasks, there is not—tic-tac-toe is a classic example. It is not clear how close humans (or technologically aided humans) are from the limits to competence in the particular domains that will matter. It is to my knowledge an open question how much ‘headroom’ there is. My guess is a lot, but it isn’t obvious.
How much headroom there is varies by task. Categories of task for which there appears to be little headroom:
- Tasks where we know what the best performance looks like, and humans can get close to it. For instance, machines cannot win more often than the best humans at Tic-tac-toe (playing within the rules) or solve Rubik’s cubes much more reliably, or extracting calories from fuel
- Tasks where humans are already be reaping most of the value—for instance, perhaps most of the value of forks is in having a handle with prongs attached to the end, and while humans continue to design slightly better ones, and machines might be able to add marginal value to that project more than twice as fast as the human designers, they cannot perform twice as well in terms of the value of each fork, because forks are already 95% as good as they can be.
- Better performance is quickly intractable. For instance, we know that for tasks in particular complexity classes, there are computational limits to how well one can perform across the board. Or for chaotic systems, there can be limits to predictability. (That is, tasks might lack headroom not because they are simple, but because they are complex. E.g. AI probably can’t predict the weather much further out than humans.)
Categories of task where a lot of headroom seems likely:
- Competitive tasks where the value of a certain level of performance depends on whether one is better or worse than one’s opponent, so that the marginal value of more performance doesn’t hit diminishing returns, as long as your opponent keeps competing and taking back what you just won. Though in one way this is like having little headroom: there’s no more value to be had—the game is zero sum. And while there might often be a lot of value to be gained by doing a bit better on the margin, still if all sides can invest, then nobody will end up better off than they were. So whether this seems more like high or low headroom depends on what we are asking exactly. Here we are asking if AI systems can do much better than humans: in a zero sum contest like this, they likely can in the sense that they can beat humans, but not in the sense of reaping anything more from the situation than the humans ever got.
- Tasks where it is twice as good to do the same task twice as fast, and where speed is bottlenecked on thinking time.
- Tasks where there is reason to think that optimal performance is radically better than we have seen. For instance, perhaps we can estimate how high Chess Elo rankings must go before reaching perfection by reasoning theoretically about the game, and perhaps it is very high (I don’t know).
- Tasks where humans appear to use very inefficient methods. For instance, it was perhaps predictable before calculators that they would be able to do mathematics much faster than humans, because humans can only keep a small number of digits in their heads, which doesn’t seem like an intrinsically hard problem. Similarly, I hear humans often use mental machinery designed for one mental activity for fairly different ones, through analogy.8 For instance, when I think about macroeconomics, I seem to be basically using my intuitions for dealing with water. When I do mathematics in general, I think I’m probably using my mental capacities for imagining physical objects.
What it might look like if this gap matters: many challenges in today’s world remain challenging for AI. Human behavior is not readily predictable or manipulable very far beyond what we have explored, only slightly more complicated schemes are feasible before the world’s uncertainties overwhelm planning; much better ads are soon met by much better immune responses; much better commercial decision-making ekes out some additional value across the board but most products were already fulfilling a lot of their potential; incredible virtual prosecutors meet incredible virtual defense attorneys and everything is as it was; there are a few rounds of attack-and-defense in various corporate strategies before a new equilibrium with broad recognition of those possibilities; conflicts and ‘social issues’ remain mostly intractable. There is a brief golden age of science before the newly low-hanging fruit are again plucked and it is only lightning fast in areas where thinking was the main bottleneck, e.g. not in medicine.
Intelligence may not be an overwhelming advantage
Intelligence is helpful for accruing power and resources, all things equal, but many other things are helpful too. For instance money, social standing, allies, evident trustworthiness, not being discriminated against (this was slightly discussed in section ‘Human success isn’t from individual intelligence’). AI systems are not guaranteed to have those in abundance. The argument assumes that any difference in intelligence in particular will eventually win out over any differences in other initial resources. I don’t know of reason to think that.
Empirical evidence does not seem to support the idea that cognitive ability is a large factor in success. Situations where one entity is much smarter or more broadly mentally competent than other entities regularly occur without the smarter one taking control over the other:
- Species exist with all levels of intelligence. Elephants have not in any sense won over gnats; they do not rule gnats; they do not have obviously more control than gnats over the environment.
- Competence does not seem to aggressively overwhelm other advantages in humans:
- Looking at the world, intuitively the big discrepancies in power are not seemingly about intelligence.
- IQ 130 humans apparently earn very roughly $6000-$18,500 per year more than average IQ humans.
- Elected representatives are apparently smarter on average, but it is a slightly shifted curve, not a radically difference.
- MENSA isn’t a major force in the world.
- Many places where people see huge success through being cognitively able are ones where they show off their intelligence to impress people, rather than actually using it for decision-making. For instance, writers, actors, song-writers, comedians, all sometimes become very successful through cognitive skills. Whereas scientists, engineers and authors of software use cognitive skills to make choices about the world, and less often become extremely rich and famous, say. If intelligence were that useful for strategic action, it seems like using it for that would be at least as powerful as showing it off. But maybe this is just an accident of which fields have winner-takes-all type dynamics.
- If we look at people who evidently have good cognitive abilities given their intellectual output, their personal lives are not obviously drastically more successful, anecdotally.
- One might counter-counter-argue that humans are very similar to one another in capability, so even if intelligence matters much more than other traits, you won’t see that by looking at the near-identical humans. This does not seem to be true. Often at least, the difference in performance between mediocre human performance and top level human performance is large, relative to the space below, iirc. For instance, in chess, the Elo difference between the best and worst players is about 2000, whereas the difference between the amateur play and random play is maybe 400-2800 (if you accept Chess StackExchange guesses as a reasonable proxy for the truth here). And in terms of AI progress, amateur human play was reached in the 50s, roughly when research began, and world champion level play was reached in 1997.
And theoretically I don’t know why one would expect greater intelligence to win out over other advantages over time. There are actually two questionable theories here: 1) Charlotte having more overall control than David at time 0 means that Charlotte will tend to have an even greater share of control at time 1. And, 2) Charlotte having more intelligence than David at time 0 means that Charlotte will have a greater share of control at time 1 even if Bob has more overall control (i.e. more of other resources) at time 1.
What it might look like if this gap matters: there are many AI systems around, and they strive for various things. They don’t hold property, or vote, or get a weight in almost anyone’s decisions, or get paid, and are generally treated with suspicion. These things on net keep them from gaining very much power. They are very persuasive speakers however and we can’t stop them from communicating, so there is a constant risk of people willingly handing them power, in response to their moving claims that they are an oppressed minority who suffer. The main thing stopping them from winning is that their position as psychopaths bent on taking power for incredibly pointless ends is widely understood.
Unclear that many goals realistically incentivise taking over the universe
I have some goals. For instance, I want some good romance. My guess is that trying to take over the universe isn’t the best way to achieve this goal. The same goes for a lot of my goals, it seems to me. Possibly I’m in error, but I spend a lot of time pursuing goals, and very little of it trying to take over the universe. Whether a particular goal is best forwarded by trying to take over the universe as a substep seems like a quantitative empirical question, to which the answer is virtually always ‘not remotely’. Don’t get me wrong: all of these goals involve some interest in taking over the universe. All things equal, if I could take over the universe for free, I do think it would help in my romantic pursuits. But taking over the universe is not free. It’s actually super duper duper expensive and hard. So for most goals arising, it doesn’t bear considering. The idea of taking over the universe as a substep is entirely laughable for almost any human goal.
So why do we think that AI goals are different? I think the thought is that it’s radically easier for AI systems to take over the world, because all they have to do is to annihilate humanity, and they are way better positioned to do that than I am, and also better positioned to survive the death of human civilization than I am. I agree that it is likely easier, but how much easier? So much easier to take it from ‘laughably unhelpful’ to ‘obviously always the best move’? This is another quantitative empirical question.
What it might look like if this gap matters: Superintelligent AI systems pursue their goals. Often they achieve them fairly well. This is somewhat contrary to ideal human thriving, but not lethal. For instance, some AI systems are trying to maximize Amazon’s market share, within broad legality. Everyone buys truly incredible amounts of stuff from Amazon, and people often wonder if it is too much stuff. At no point does attempting to murder all humans seem like the best strategy for this.
Quantity of new cognitive labor is an empirical question, not addressed
Whether some set of AI systems can take over the world with their new intelligence probably depends how much total cognitive labor they represent. For instance, if they are in total slightly more capable than von Neumann, they probably can’t take over the world. If they are together as capable (in some sense) as a million 21st Century human civilizations, then they probably can (at least in the 21st Century).
It also matters how much of that is goal-directed at all, and highly intelligent, and how much of that is directed at achieving the AI systems’ own goals rather than those we intended them for, and how much of that is directed at taking over the world.
If we continued to build hardware, presumably at some point AI systems would account for most of the cognitive labor in the world. But if there is first an extended period of more minimal advanced AI presence, that would probably prevent an immediate death outcome, and improve humanity’s prospects for controlling a slow-moving AI power grab.
What it might look like if this gap matters: when advanced AI is developed, there is a lot of new cognitive labor in the world, but it is a minuscule fraction of all of the cognitive labor in the world. A large part of it is not goal-directed at all, and of that, most of the new AI thought is applied to tasks it was intended for. Thus what part of it is spent on scheming to grab power for AI systems is too small to grab much power quickly. The amount of AI cognitive labor grows fast over time, and in several decades it is most of the cognitive labor, but humanity has had extensive experience dealing with its power grabbing.
Speed of intelligence growth is ambiguous
The idea that a superhuman AI would be able to rapidly destroy the world seems prima facie unlikely, since no other entity has ever done that. Two common broad arguments for it:
- There will be a feedback loop in which intelligent AI makes more intelligent AI repeatedly until AI is very intelligent.
- Very small differences in brains seem to correspond to very large differences in performance, based on observing humans and other apes. Thus any movement past human-level will take us to unimaginably superhuman level.
These both seem questionable.
- Feedback loops can happen at very different rates. Identifying a feedback loop empirically does not signify an explosion of whatever you are looking at. For instance, technology is already helping improve technology. To get to a confident conclusion of doom, you need evidence that the feedback loop is fast.
- It does not seem clear that small improvements in brains lead to large changes in intelligence in general, or will do on the relevant margin. Small differences between humans and other primates might include those helpful for communication (see Section ‘Human success isn’t from individual intelligence’), which do not seem relevant here. If there were a particularly powerful cognitive development between chimps and humans, it is unclear that AI researchers find that same insight at the same point in the process (rather than at some other time).
A large number of other arguments have been posed for expecting very fast growth in intelligence at around human level. I previously made a list of them with counterarguments, though none seemed very compelling. Overall, I don’t know of strong reason to expect very fast growth in AI capabilities at around human-level AI performance, though I hear such arguments might exist.
What it would look like if this gap mattered: AI systems would at some point perform at around human level at various tasks, and would contribute to AI research, along with everything else. This would contribute to progress to an extent familiar from other technological progress feedback, and would not e.g. lead to a superintelligent AI system in minutes.
Key concepts are vague
Concepts such as ‘control’, ‘power’, and ‘alignment with human values’ all seem vague. ‘Control’ is not zero sum (as seemingly assumed) and is somewhat hard to pin down, I claim. What an ‘aligned’ entity is exactly seems to be contentious in the AI safety community, but I don’t know the details. My guess is that upon further probing, these conceptual issues are resolvable in a way that doesn’t endanger the argument, but I don’t know. I’m not going to go into this here.
What it might look like if this gap matters: upon thinking more, we realize that our concerns were confused. Things go fine with AI in ways that seem obvious in retrospect. This might look like it did for people concerned about the ‘population bomb’ or as it did for me in some of my youthful concerns about sustainability: there was a compelling abstract argument for a problem, and the reality didn’t fit the abstractions well enough to play out as predicted.
D. Contra the whole argument
The argument overall proves too much about corporations
Here is the argument again, but modified to be about corporations. A couple of pieces don’t carry over, but they don’t seem integral.
I. Any given corporation is likely to be ‘goal-directed’
Reasons to expect this:
- Goal-directed behavior is likely to be valuable in corporations, e.g. economically
Goal-directed entities may tend to arise from machine learning training processes not intending to create them (at least via the methods that are likely to be used).- ‘Coherence arguments’ may imply that systems with some goal-directedness will become more strongly goal-directed over time.
II. If goal-directed superhuman corporations are built, their desired outcomes will probably be about as bad as an empty universe by human lights
Reasons to expect this:
- Finding useful goals that aren’t extinction-level bad appears to be hard: we don’t have a way to usefully point at human goals, and divergences from human goals seem likely to produce goals that are in intense conflict with human goals, due to a) most goals producing convergent incentives for controlling everything, and b) value being ‘fragile’, such that an entity with ‘similar’ values will generally create a future of virtually no value.
- Finding goals that are extinction-level bad and temporarily useful appears to be easy: for example, corporations with the sole objective ‘maximize company revenue’ might profit for a time before gathering the influence and wherewithal to pursue the goal in ways that blatantly harm society.
- Even if humanity found acceptable goals, giving a corporation any specific goals appears to be hard. We don’t know of any procedure to do it
, and we have theoretical reasons to expect that AI systems produced through machine learning training will generally end up with goals other than those that they were trained according to. Randomly aberrant goals resulting are probably extinction-level bad, for reasons described in II.1 above.
III. If most goal-directed corporations have bad goals, the future will very likely be bad
That is, a set of ill-motivated goal-directed corporations, of a scale likely to occur, would be capable of taking control of the future from humans. This is supported by at least one of the following being true:
- A corporation would destroy humanity rapidly. This may be via ultra-powerful capabilities at e.g. technology design and strategic scheming, or through gaining such powers in an ‘intelligence explosion‘ (self-improvement cycle). Either of those things may happen either through exceptional heights of intelligence being reached or through highly destructive ideas being available to minds only mildly beyond our own.
- Superhuman AI would gradually come to control the future via accruing power and resources. Power and resources would be more available to the corporation than to humans on average, because of the corporation having far greater intelligence.
This argument does point at real issues with corporations, but we do not generally consider such issues existentially deadly.
One might argue that there are defeating reasons that corporations do not destroy the world: they are made of humans so can be somewhat reined in; they are not smart enough; they are not coherent enough. But in that case, the original argument needs to make reference to these things, so that they apply to one and not the other.
What it might look like if this counterargument matters: something like the current world. There are large and powerful systems doing things vastly beyond the ability of individual humans, and acting in a definitively goal-directed way. We have a vague understanding of their goals, and do not assume that they are coherent. Their goals are clearly not aligned with human goals, but they have enough overlap that many people are broadly in favor of their existence. They seek power. This all causes some problems, but problems within the power of humans and other organized human groups to keep under control, for some definition of ‘under control’.
Conclusion
I think there are quite a few gaps in the argument, as I understand it. My current guess (prior to reviewing other arguments and integrating things carefully) is that enough uncertainties might resolve in the dangerous directions that existential risk from AI is a reasonable concern. I don’t at present though see how one would come to think it was overwhelmingly likely.
-
That is, systems that are somewhat more capable than the most capable human. ↩
-
Based on countless conversations in the AI risk community, and various reading. ↩
-
Though not all: you might have an easily satiable utility function, or only care about the near future. ↩
-
We are talking about divergence in a poorly specified multi-dimensional space, so it isn’t going to be a fixed distance in every direction from the ideal point. It could theoretically be zero distance on some dimensions, such that if AI was misaligned at all in those directions it was catastrophic. My point here is merely that there is some area larger than a point. ↩
-
The Secrets of Our Success seems to be the canonical reference for this, but I haven’t read it. I don’t know how controversial this is, but also don’t presently see how it could fail to be true. ↩
-
See section ‘Intelligence may not be an overwhelming advantage’. ↩
-
E.g. for the metric ‘hardness of math problem solvable’, maybe no human can solve a level 10 math problem, but several can solve 9s. Then human society as a whole also can’t solve a 10. So the first AI that can is only mildly surpassing the best human, but is at the same time surpassing all of human society. ↩
-
Probably I have this impression from reading Steven Pinker at some point. ↩
-
A game of mattering
When I have an overwhelming number of things to do, and insufficient native urge to do them, I often arrange them into a kind of game for myself. The nature and appeal of this game has been relatively stable for about a year, after many years of evolution, so this seems like a reasonable time to share it. I also play it when I just want to structure my day and am in the mood for it. I currently play something like two or three times a week.
The game
The basic idea is to lay out the tasks in time a bit like obstacles in a platformer or steps in Dance Dance Revolution, then race through the obstacle course grabbing them under consistently high-but-doable time pressure.
Here’s how to play:
- Draw a grid with as many rows as there are remaining hours in your hoped for productive day, and ~3 columns. Each box stands for a particular ~20 minute period (I sometimes play with 15m or 30m periods.)
- Lay out the gameboard: break the stuff you want to do into appropriate units, henceforth ‘items’. An item should fit comfortably in the length of a box, and it should be easy enough to verify completion. (This can be achieved through house rules such as ‘do x a tiny bit = do it until I have a sense that an appropriate tiny bit has been done’ as long as you are happy applying them). Space items out a decent amount so that the whole course is clearly feasible. Include everything you want to do in the day, including nice or relaxing things, or break activities. Drinks, snacks, tiny bouts of exercise, looking at news sites for 5 minutes, etc. Design the track thoughtfully, with hard bouts followed by relief before the next hard bout.
- To play, start in the first box, then move through the boxes according to the time of day. The goal in playing is to collect as many items as you can, as you are forced along the track by the passage of time. You can collect an item by doing the task in or before you get to the box it is in. If it isn’t done by the end of the box, it gets left behind. However if you clear any box entirely, you get to move one item anywhere on the gameboard. So you can rescue something from the past, or rearrange the future to make it more feasible, or if everything is perfect, you can add an entirely new item somewhere.
I used to play this with tiny post-it stickers, which I would gather in a large moving pile, acting as a counter:


Now I just draw the whole thing. Crossed out = collected; [] = rescued from the past, now implicitly in the final box; dot in the lower right = box cleared; dot next to item = task done but item stuck in the past (can be collected immediately if rescued).

Why is this good?
I think a basic problem with working on a big pile of things in a big expanse of time is that if you work or not during any particular minute, it feels like it makes nearly no difference to the expectation of success. I’m not quite sure why this is—in fact if I don’t work this minute, I’m going to get one minute less work done. But it feels like if I don’t work this minute, I only need to work a smidgen faster on average to get any particular amount of work done, so what does it matter if I work now or later? And if i had some particular goal (e.g. finishing writing some massive text today), it’s unlikely that my other efforts will get me exactly to the line where this minute pushed me over—probably I will either succeed with hours to spare (haha) or fail hours from my goals.
I picture what’s going on as vaguely something like this—there is often some amount of work that is going to make your success likely, and if you know that you are on a locally steep part of the curve, it is more motivating than if you are either far away from the steep part or don’t know where you are:

Yet on the other hand, the appeal of various non-work activities this specific minute might be the most distinct and tangible things in the world. So when there is a lot to be done in a long time, not working often looks more exciting than working, even if a more rational accounting would disagree.
Having a single specific thing to do within minutes is much more compelling: the task and the time are lined up so that my action right now matters. Slacking this minute is the difference between success and failure.
It feels very different to have one email to deal with in three minutes and to have a thousand to deal with in next fifty hours.
One might naively respond to this issue by breaking up one’s tasks into tiny chunks, then laying them out in a day of tiny time boxes, then aiming for each to happen by the end of its allotment. But this will be terrible. A few boxes in, either you’ll be ahead or behind. And either way, your immediate actions have drifted away from feeling like they matter. If you are ahead, the pressure is off: you’ll probably succeed at the next increment whether or not you work hard now. If behind, you are definitely going to fail at doing the next box on time, and probably some others, and your present work is for an increased chance of catching up at some vague future box, much like before you had these boxes. (Plus your activities are no longer in line with what your plan was, which for me makes it tempting to scrap the whole thing and do something else.)
A big innovation of this game is to instead ensure that you keep meeting tasks one at a time where each one matters in its moment, as in a game like Beat Saber or Dance Dance Revolution. The game achieves this by adjusting the slack to keep the next ten minutes’ action near the actually-mattering-to-success region all day. If you get behind you have to give up on items and move forward, so you aren’t left struggling for a low probability of catching up. If you get ahead, you add more items and thus tighten the slack.
A thing I like about this is that it actually makes the activity more genuinely fun and compelling, and doesn’t involve trying to trick or uncomfortably binding oneself. It is superficially a lot like a ‘productivity hack’, but I associate these with somehow manipulating or forcing yourself to do something that you at some level have real reason to dislike. I expect such tricks to fail, and I don’t think I want them to succeed.
This seems different: I think humans are just genuinely better at being in an enjoyable flow state when their activities have certain structures that are genuinely compatible with a variety of tasks. Beat saber wouldn’t be fun if all the boxes were just sitting in a giant pile and you had to beat your way through as many as you could over an hour. But with the boxes approaching one at a time, at a manageable rate, where what you do in each moment matters, it really is fun (for many people, I hear—I actually don’t love it, but I do appreciate this particular aspect). The same thing that makes Beat Saber more fun than Saber-a-bunch-of-boxes-on-your-own-schedule can genuinely also be applied to giant piles of tasks.
The fact that this game has lasted a year in my life and I come back to it with verve points to it not being an enemy to any major part of myself.
Another promising way of seeing this game is that this structure lets you see more clearly the true importance of each spent minute, when you were by default in error. Whereas for instance playing Civ IV for five minutes every time you do work (another sometimes way-of-being of mine) is less like causing yourself to perceive reality truly and more like trying to build an alternate incentive structure out of your mistaken perception, that adds up to rational behavior in the real world.
If anyone else tries this, I’m curious to hear how it goes. My above explanation of its merit suggests it might be of broad value. But I also know that perhaps nobody in the world likes organizing things into little boxes as much as I do, so that could also be the main thing going on.
-
Podcasts on surveys, slower AI, AI arguments
I recently talked to Michael Trazzi for his podcast, The Inside View. It just came out, so if that’s a conversation you want to sit in on, do so here [ETA: or read it here].
The main topics were the survey of ML folk I recently ran, and my thoughts on moving more slowly on potentially world-threatening AI research (which is to say, AI research in general, according to the median surveyed ML researcher…). I also bet him a thousand dollars to his hundred that AI would not make blogging way more efficient in two years, if I recall. (I forget the exact terms, and there’s no way I’m listening to myself talk for that long to find out. If anyone else learns, I’m curious what I agreed to.)
For completeness of podcast reporting: I forgot to mention that I also talked to Daniel Filan on AXRP, like a year ago. In other old news, I am opposed to the vibe of time-sensitivity often implicit in the public conversation.
-
What do ML researchers think about AI in 2022?
Crossposted from AI Impacts
AI Impacts just finished collecting data from a new survey of ML researchers, as similar to the 2016 one as practical, aside from a couple of new questions that seemed too interesting not to add.
This page reports on it preliminarily, and we’ll be adding more details there. But so far, some things that might interest you:
- 37 years until a 50% chance of HLMI according to a complicated aggregate forecast (and biasedly not including data from questions about the conceptually similar Full Automation of Labor, which in 2016 prompted strikingly later estimates). This 2059 aggregate HLMI timeline has become about eight years shorter in the six years since 2016, when the aggregate prediction was 2061, or 45 years out. Note that all of these estimates are conditional on “human scientific activity continu[ing] without major negative disruption.”
- P(extremely bad outcome)=5% The median respondent believes the probability that the long-run effect of advanced AI on humanity will be “extremely bad (e.g., human extinction)” is 5%. This is the same as it was in 2016 (though Zhang et al 2022 found 2% in a similar but non-identical question). Many respondents put the chance substantially higher: 48% of respondents gave at least 10% chance of an extremely bad outcome. Though another 25% put it at 0%.
- Explicit P(doom)=5-10% The levels of badness involved in that last question seemed ambiguous in retrospect, so I added two new questions about human extinction explicitly. The median respondent’s probability of x-risk from humans failing to control AI1 was 10%, weirdly more than median chance of human extinction from AI in general2, at 5%. This might just be because different people got these questions and the median is quite near the divide between 5% and 10%. The most interesting thing here is probably that these are both very high—it seems the ‘extremely bad outcome’ numbers in the old question were not just catastrophizing merely disastrous AI outcomes.
- Support for AI safety research is up: 69% of respondents believe society should prioritize AI safety research “more” or “much more” than it is currently prioritized, up from 49% in 2016.
- The median respondent thinks there is an “about even chance” that an argument given for an intelligence explosion is broadly correct. The median respondent also believes machine intelligence will probably (60%) be “vastly better than humans at all professions” within 30 years of HLMI, and that the rate of global technological improvement will probably (80%) dramatically increase (e.g., by a factor of ten) as a result of machine intelligence within 30 years of HLMI.
- Years/probabilities framing effect persists: if you ask people for probabilities of things occurring in a fixed number of years, you get later estimates than if you ask for the number of years until a fixed probability will obtain. This looked very robust in 2016, and shows up again in the 2022 HLMI data. Looking at just the people we asked for years, the aggregate forecast is 29 years, whereas it is 46 years for those asked for probabilities. (We haven’t checked in other data or for the bigger framing effect yet.)
- Predictions vary a lot. Pictured below: the attempted reconstructions of people’s probabilities of HLMI over time, which feed into the aggregate number above. There are few times and probabilities that someone doesn’t basically endorse the combination of.
- You can download the data here (slightly cleaned and anonymized) and do your own analysis. (If you do, I encourage you to share it!)
Individual inferred gamma distributions
The survey had a lot of questions (randomized between participants to make it a reasonable length for any given person), so this blog post doesn’t cover much of it. A bit more is on the page and more will be added.
Thanks to many people for help and support with this project! (Many but probably not all listed on the survey page.)
Cover image: Probably a bootstrap confidence interval around an aggregate of the above forest of inferred gamma distributions, but honestly everyone who can be sure about that sort of thing went to bed a while ago. So, one for a future update. I have more confidently held views on whether one should let uncertainty be the enemy of putting things up.
- Or, ‘human inability to control future advanced AI systems causing human extinction or similarly permanent and severe disempowerment of the human species’
- That is, ‘future AI advances causing human extinction or similarly permanent and severe disempowerment of the human species’
</div><div id="custom_html-19" class="widget_text mh-widget mh-posts-2 widget_custom_html"><div class="textwidget custom-html-widget"><div> -
Why do people avoid vaccination?
I’ve been fairly confused by the popularity in the US of remaining unvaccinated, in the face of seemingly a non-negligible, relatively immediate personal chance of death or intense illness. And due to the bubbliness of society, I don’t actually seem to know unvaccinated people to ask about it. So in the recent covid survey I ran, I asked people who hadn’t had covid (and thus for whom I didn’t have more pressing questions) whether they were vaccinated, and if not why not. (Note though that these people are 20-40 years old, so not at huge risk of death.)
Their responses:
- I don’t think I need it, I don’t think covid is a big deal, I don’t think the vaccine works and the more the government/media pushes it the more I don’t want to ever get it. It should be a private decision between someone and their doctor, not Joe Biden and CNN saying comply or be kicked out of society.
- I still dont trust the information and safety claims made by the crooked FDA and CDC. Needs more research and study.
- I had a scary vaccine reaction previously.
- I am only 32 years old and in decent health so I think I would be fine if I caught COVID. It has almost been two years since the pandemic started and I haven’t gotten sick besides some minor colds. I would rather rely on natural immunity instead of the vaccine.
- dont want one
- Other health issues where my Doctor wants me to wait to get vaccinated.
- I think it is poison at worst and ineffective at best. Also the way the pushed it came off like a homeless man trying to lure me into an ally. The vaccine issue has made me lose 100% trust and faith in media and government i do not believe or trust anything from them anymore
- I have anxiety problems and other health issues.
- I’m actually scheduled to get a vaccination, I’m simply waiting for my appointment date.
- The places where the vaccination is available are always crowded and I am somewhat afraid of being outdoors or indoors in large crowds for too long these days.
- I am extremely skeptical of this “vaccine”, which has been proven ineffective (vaccinated people keep getting it, and what’s with all of the boosters?!) and has caused too many deaths and/or serious health issues/emergencies. I’ll take my chances on Covid any day over a “vaccine” that magically appeared from 8+ pharmaceutical companies in such an astonishingly short time. That is unheard of, and there is no way to know what is really in it, and what kind of problems those who are ignorant and fearful enough to get it will face later on down the road (that is, if they don’t die from the “vaccinations” themselves. The fact that the government has bribed, coerced, and is trying to FORCE everyone to get this “vaccine” is unprecedented, and quite frankly terrifying and sinister to me. I will NEVER allow a forced injection of god knows what into my own body, as that is wrong in every way there is. Vaccines allegedly keep those who get them safe from contracting whatever it is the vaccine is made for, so why would it be anyone’s business whether or not someone else is vaccinated? The Let’s Go Brandon administration and the dumbocrats that were fearmongering before the administration was even in place have done this by design. Spread fear, mistrust, and divisiveness, and lock people down to isolate them and make them suspicious and fearful of one another. Divide and conquer, because the fascist wannabe communists know that it is the only way to indulge their scummy self-serving agendas. United we stand.
- For health reasons.
- I’m not at high risk, so I don’t need it immediately. Waiting to see how effective it is.
- I don’t think it’s efficient…the prospect of being jabbed by endless boosters doesn’t appeal to me
- I’ve never had covid.
- I don’t trust the vaccine and have not have gotten covid since the pandemic started. Plus all of the misinformation surrounding covid, from the news media to social media sites. I just don’t know what to believe anymore but I feel that not getting vaccinated is the best option for me.
- I am still skeptical of the vaccine since people are still catching covid and its variants
- It doesn’t stop the transmission, or stop you from getting covid. I am at low risk anyways.
- I am at very low risk of infection as I do not work and wouldn’t accept any non-remote work. I also do not have any friends or family in the state where I moved to last year and I do not drink so I don’t go out to bars or events, or even restaurants.
- I simply have no trust in the big pharmacy and little more in the government. Throw in the fact that the vaccine was created too quickly and while it claims to have lowered infection rates and the severity of COVID-19, I’ve known several people who have been infected and they were fully vaccinated. In addition, I’ve seen many news articles reporting the same. Why should I receive a vaccine that provides such weak protection?
- Transportation and access. If a pill form or some self-administering option were available, I would.
- I don’t trust it.
- I have chosen not to take the vaccine
- Because I think its the Governments agenda to start killing people. I don’t trust Big Pharma or the Government. Also, people still get covid with the vaccine, seems like a waste of time.
- I live in Ohio, kinda wanna die. Also, it doesnt even dent the new variants; you still ge tit.
- do not trust them
- Because I believe that the vaccine is part of a either depopulation plan, or a tracking device. Either way there is no logical reason to get it.
- I am hesitant because of the possible side effects long-term because not much is known about it.
- I don’t see the benefit since I am not really at risk from covid.
- It’s against my religion.
- I don’t need a covid vaccination.
- I’m concerned about possible serious side effects from the vaccine that may show up some time down the road.
- Normally, I would consider it, but the talk of forced mandates has really soured me to it. I dont believe in taking away people’s health freedoms like that. I think it’s an insane intursion on civil liberties, and I fear if we all just accept it, we will become like Australia
- I only leave the house once or twice a week so it never really felt necessary to me.
The biggest themes mentioned here seem to be distrust or hostility regarding the government and media and their various pro-vaccination pressurings, and the impression that the vaccine doesn’t work. (I wonder how much that one is relative to an expectation of ‘very occasional breakthrough cases’ that one might also trace to someone’s questionable communication choices.) An unspoken theme is arguably being in possession of relatively little information (like, what’s going on with the person who is still waiting to find out if the vaccines are effective? And do people just not know that the vaccine reduces the downside of covid, even if it is still possible to get it? Or do all of these people know things I don’t?).
I wonder if much good could be done in this kind of situation with some kind of clearly independent and apolitical personal policy research institution, who prioritized being trustworthy and accurate. Like, I don’t trust the government or media especially either on this, but I and people I do trust have a decent amount of research capacity and familiarity with things like academic papers, so we arguably have an unusually good shot at figuring out the situation without having to make reference to the government or media much (assuming there aren’t more intense conspiracies afoot, in which case we will end up dead or tracking-deviced, I suppose). If I wasn’t in such a position, I feel like I’d pay a decent amount for someone to think about such things for me. I guess this is related to the service that doctors are meant to provide, though the thing I imagine would look very different to real doctors in practice.
- I don’t think I need it, I don’t think covid is a big deal, I don’t think the vaccine works and the more the government/media pushes it the more I don’t want to ever get it. It should be a private decision between someone and their doctor, not Joe Biden and CNN saying comply or be kicked out of society.
-
Punishing the good
Should you punish people for wronging others, or for making the wrong call about wronging others?
For example:
- A newspaper sends me annoying emails all the time, but suppose that empirically if they didn’t behave like this, they would get markedly fewer subscribers, and may not survive. And suppose their survival is in fact worth a little annoyance for a lot of people, we all agree. Such that if I was in their position, I agree that I would send out the annoying emails. Should I resent them and unsubscribe from their paper for their antisocial behavior, or praise them and be friendly because overall I think they made the right call?
- Suppose Bob eats beef, which he thinks makes him feel somewhat better and so be better able to carry out his job as a diplomat negotiating issues in which tens of thousands of lives are at stake. He also thinks it is pretty bad for the cows, but worth it on net. Suppose he’s right about all of this. Five hundred years later, carnivory is illegal and hated, and historians report that Bob, while in other regards a hero, did eat beef. Should the people of 2521 think of Bob as an ambiguous figure, worthy of both pride and contempt? or should they treat him as purely a hero, who made the best choice in his circumstances?
I have one intuition that says, ‘how can you punish someone for doing the very best thing they could have done? What did you want them to do? And are you going to not punish the alternative person, who made a worse choice for the world, but didn’t harm someone in the process? Are you just going to punish everyone different amounts?’
But an argument for the other side—for punishing people for doing the right thing—is that it is needed to get the incentives straight. If Alice does $100 of harm to Bruce to provide $1000 of help to Carrie, then let’s suppose that that’s good (ignoring the potential violation of property rights, which seems like it shouldn’t be ignored ultimately). But if we let such things pass, then Alice might also do this when she guesses that is only worth $60 to Carrie, if she cares about Carrie more than Bruce. Whereas if we always punish Alice just as much as she harmed Bruce, then she will take the action exactly when she would think it worth it if it was her own welfare at stake, rather than Bruce’s. (This is just the general argument for internalizing externalities - having people pay for the costs they impose on others.)
This resolution is weirder to the extent that the punishment is in the form of social disgrace and the like. It’s one thing to charge Bob money for his harms to cows, and another to go around saying ‘Bob made the best altruistic decisions he could, and I would do the same in his place. Also I do think he’s contemptible.’
It also leaves Bob in a weird position, in which he feels fine about his decision to eat beef, but also considers himself a bit of a reprehensible baddie. Should this bother him? Should he try to reform?
I’m still inclined toward punishing such people, or alternately to think that the issue should be treated with more nuance than I have done, e.g. distinguishing punishments from others’ opinions of you, and more straightforward punishments.
-
Typology of blog posts that don't always add anything clear and insightful
I used to think a good blog post should basically be a description of a novel insight.
To break it down more, on this view:
- A blog post should have a propositional claim (e.g. ‘the biggest externalities are from noise pollution’, or ‘noise pollution is a concept’ vs. expression of someone’s feelings produced by externalities, or a series of reflections on externalities). A ‘propositional claim’ here can be described straightforwardly in words, and usually conveys information (i.e. they say the world is one way instead of another way).
- It should be a general claim—i.e. applicable to many times and places and counterfactuals (e.g. ‘here is how tragedies of the commons work: …’ vs. ‘here is a thing that happened to me yesterday: …’)
- It should be a novel claim(e.g. a new reason to doubt one of the explanations put forward for the demographic transition)
- The claim should be described, which is to imply that the content should be:
- Verbal (or otherwise symbolic, e.g. a table of numbers surrounded by text would count)
- Explicit (saying the things it means, rather than alluding to them)
- Mostly concerned with conveying the relevant propositions (vs. for instance mostly concerned with affecting the reader’s mood or beliefs directly)
I probably would have agreed that the odd vignette was also a good blog post, but ideally it should be contained in some explicit discussion of what was to be learned from it. I probably wouldn’t have held my more recent Worldly Positions blog1 in high esteem.
I now think that departures from all of these things are often good. So in the spirit of novel descriptions of explicit and general claims, I have made a typology of different combinations of these axes.
Before getting to it, I’ll explain some part of the value of each category that I think I overlooked, for anyone similar to my twenty year old self.
Worthy non-propositional-claim content
Minds have many characteristics other than propositional beliefs. For instance, they can have feelings and attitudes and intuitions and grokkings and senses. They can meditate and chop onions quickly and look on the bright side and tend to think in terms of systems. They can also have different versions of ‘beliefs’ that don’t necessarily correspond to differences in what propositions they would assent to. For instance, they can say ‘it’s good to exercise’, or they can viscerally anticipate a better future when they choose to exercise. And even among straightforward beliefs held by minds, there are many that aren’t easily expressed in words. For instance, I have an impression of what summer evenings in the garden of a lively country restaurant were like, but to convey that sense to you is an art, and probably involves saying different propositional things in the hope that your mind will fill in the same whatever-else in the gaps. So this belief doesn’t seem to live in my mind in a simple propositional form, nor easily make its way into one.
All of this suggests that the set of things that you might want to communicate to a mind is large and contains much that is not naturally propositional.2
Minds can also take many inputs other than propositional claims. For instance, instructions and remindings and stories and music and suggestions implicit in propositional claims and body language and images. So if you want to make available a different way of being to a mind—for instance you want it to find salient the instability of the global system—then it’s not obvious that propositional claims are the best way.
Given that minds can take many non-propositional inputs, and take many non-propositional states, you should just expect that there are a lot of things to be said that aren’t naturally propositional, in form or content. You should expect messages where the payload is intended to influence a mind’s non-propositional states, and ones where the mode of communication is not propositional.
…in communicating propositional claims
There are different versions of ‘understanding’ a proposition. I like to distinguish ‘knowing’ or ‘understanding’ a thing — which is to say, seeing it fit into your abstract model of the world, being inclined to assent to it — and ‘realizing’ it — intuitively experiencing its truth in the world that you live in. Joe Carlsmith explores this distinction at more length, and gives an example I like:
If asked, one would agree that the people one sees on a day to day basis — on the subway, at parties, at work — all have richly detailed and complex inner lives, struggles, histories, perspectives; but this fact isn’t always present and vivid in one’s lived world; and when it becomes so, it can make an important difference to one’s ethical orientation, even if the propositions one assents to have not obviously changed.
I repeatedly have the experience of ‘already knowing’ some obvious thing that people always say for ages before ‘realizing’ it. For instance, ‘the map is not the territory’. (“Of course the map isn’t the territory. Why would it be? That would be some stupid mistake, thinking that the map was the territory. Like, what would your model of the situation even be like? That the place you live is also your own mind?”) Then at some point it actually hits me that stuff that seems to be in the world ISN’T IN THE WORLD; WHAT SEEMS LIKE THE WORLD IS MY OWN MIND’S IMAGE OF THE WORLD. For instance, long after seeming to know that ‘the map isn’t the territory’ I was astonished to realize that those things that are just boring in their basic essence, like sports statistics and home care magazines, things that seem to be fundamentally drab, are not like that at all. They gleam with just as much allure as the things I am most compelled by, from many vantage points out there—just not mine. And in such a case I say to myself, ‘Oh wow, I just realized something…huh, I guess it is that the map is not the territory…but I knew that?’. Probably reading this, you are still thinking, ‘um yes, you weren’t aware that boringness is person-dependent?’ And I was aware of that. I ‘knew’ it. And I even knew it in some intuitively available ways—for instance, just because I find Married at First Sight interesting, I did not expect my boyfriend to find it so. In particular, in approaching my boyfriend with the news that I have been watching a bunch of Married at First Sight, I viscerally did not expect ‘boyfriend sympathizes with appeal of objectively excellent show’ type observations (in fact he liked it, and I was in fact surprised). But still the boringness of other subjects is depicted to me as part of them, like being red is depicted as in the world (whereas ‘liable to reduce my hunger’ say, is I think more accurately represented by my mind as a feature of myself). And ‘realizing’ that that isn’t right changes how the world that I spend my concrete days in seems.
(I know I have hardly explained or defended this claim that ‘realizing’ is a thing, and important, but I’m not going to do that properly here.)
All of these ‘realizations’ seem to be non-propositional. You already had some proposition, and then you get something else. I think of ‘realizing’ a proposition as acquiring a related non-proposition. To realize the proposition ‘other people have inner lives’ is to take in some non-proposition. Perhaps a spacious sense of those other minds being right there around you. If you are communicating a proposition, to have it actually realized, you want to get its non-proposition partner into the recipient’s mind also. This isn’t really right, because each proposition probably has a multitude of intuitive realizations of it, and each intuitive sense of the world could be part of appreciating a multitude of different propositions. But at any rate, communicating a proposition well, so that the other person can really make use of it, often seems to involve conveying a lot of its non-propositional brethren.
Worthy non-descriptive communication
Closely related to non-propositional content is non-descriptive communication, which I shall call ‘evocative’ communication.
I’m thinking of a few different axes as being related to descriptiveness of communication:
- Verbalness (consisting of words, e.g. “donkeys are nice” vs. a video of a nice donkey)
- Explicitness (saying in words the thing you mean, rather than demonstrating it or suggesting it or subtly causing it to creep into the background of the picture you are painting without naming it. E.g. “I want us to follow this protocol” vs. “Most reasonable people are following this protocol now”)
- Neutrality (not setting out to affect the readers’ emotions except via content itself)
I think of the most vanilla communication as being explicit, verbal and neutral. And this seems pretty good for conveying propositional content. But I suspect that non-propositional content is often conveyed better through evocative communication.
(Or perhaps it is more like: communicating propositional claims explicitly with language is uniquely easy, because explicit language is basically a system we set up for communicating, and propositions are a kind of message that is uniquely well suited to it. But once we leave the set of things that are well communicated in this way, and given that there are lots of other ways to communicate things, non-descriptive forms of communication are much more likely to be helpful than they were.)
Relatedly, I think non-descriptive communication can be helpful in making the ‘realizing’ versions of propositional claims available to minds. That is, in really showing them to us. So in that way, evocative communication seems also potentially valuable for communicating propositional content well.
Worthy communication of non-propositional things descriptively
Going the opposite way—trying to communicate ineffable things in words—also seems valuable, because a) groping nearby propositionally does contribute to understanding, and b) only understanding things in ineffable ways leaves them unavailable to our reasoning faculties in important ways.
Worthy non-generality
I thought that if things were not general, then they were particularly unimportant to talk about. All things equal, isn’t it way better to understand a broad class of things better than a single thing?
Some ways this is misleading:
- Understanding specific things is often basically a prerequisite for understanding general things. For instance, devising a general theory of circumstances under which arms races develop will be harder without specific information about the behavior of specific nations historically, to inspire or constrain your theorizing
- Understanding specific things one after another will often automatically lead to your having an intuitive general model, through some kind of brain magic, even in cases where you would have had a hard time making an explicit model. For instance, after you have seen a thousand small disputes run their course, you might have a pretty good guess about how the current dispute will go, even if you couldn’t begin to describe a theory of argumentation for the relevant community.
- Specific things are often broadly relevant to the specific world that you live in. For instance, exactly what happened in a particular past war might determine what current obligations should be and what sentiments are warranted, and who is owed, and what particular current parties might be expected to want or take for granted. Which is perhaps only of much interest in a narrow range of circumstances, but if they are the circumstances in which we will live for decades, it might be consistently material.
Worthy non-originality of content
On my naive model, you don’t want to repeat something that someone else said, because there is implicitly no value in the repetition—the thing has already been said, so re-saying adds nothing and seems to imply that you are either ignorant or hoping to dupe ignorant others into giving you undeserved credit.
But on a model where many claims are easy enough to accept, but hard to realize, things look very different. The first time someone writes down an idea, the chances of it really getting through to anyone with much of its full power are low. The typical reader needs to meet the idea repeatedly, from different angles, to start to realize it.
In a world like that, a lot of value comes from rehashing older ideas. Also in that world, rehashing isn’t the easy cashing in of someone else’s work. Writing something in a way that might really reach some people who haven’t yet been reached is its own art.
Worthy non-originality of communication
I think I also kind of imagined that once an idea had been put into the ‘public arena’ then the job was done. But another way in which unoriginality is incredibly valuable is that each person can only see such a minuscule fraction of what has ever been written or created, and they can’t even see what they can’t see, that locating particularly apt bits and sharing them with the right audience can be as valuable as writing the thing in the first place. This is curating and signal boosting. For these, you don’t even need to write anything original. But again, doing them well is not trivial. Knowing which of the cornucopia of content should be shown to someone is a hard intellectual task.
Typology
Here is my tentative four-dimensional typology of kinds of blog posts. Any blog post maps to a path from some kind of content on the left, through some kind of communication to publication on the right. Content varies on two axes: generality and propositionalness. Communication varies in evocativeness. And blog posts themselves vary in how early in this pipeline the author adds value. For instance, among posts with a general propositional idea as their content, communicated in a non-propositional way, there are ones where the author came up with the idea, ones where the author took someone else’s idea and wrote something evocative about it, and ones that are repostings of either of the above. Thus, somewhat confusingly, there are 16 (pathways from left to right) x 3 (steps per pathway) = 46 total blog post types represented here, not the 36 you might expect from the number of squares.
I include a random assortment of examples, some obscure, zooming probably required (apologies).

Main updates
- Lots of worthy things are hard to describe in words
- ‘Realizing’ is a thing, and valuable, and different to understanding
- Details can be good
- Having ideas is not obviously the main place one can add value
Takeaways
- It’s good to write all manner of different kinds of blog posts
- It’s good to just take other people’s ideas and write blog posts about them, especially of different kinds than the original blog posts
- It’s good to just take one’s own ideas and write second or third blog posts saying exactly the same thing in different ways
Other thoughts
These different sorts of blog posts aren’t always valuable, of course. They have to be done well. Compellingly writing about something that isn’t worthy of people’s attention, or curating the wrong things can be as bad as the good versions of these things are good.
Epistemic status: overall I expect to find that this post is badly wrong in at least one way in short order, but to be sufficiently interested in other things that I don’t get around to fixing it. Another good thing about rehashing others ideas is that you can make subtle edits where they are wrong.
Notes
-
The ecology of conviction
Supposing that sincerity has declined, why?
It feels natural to me that sincere enthusiasms should be rare relative to criticism and half-heartedness. But I would have thought this was born of fairly basic features of the situation, and so wouldn’t change over time.
It seems clearly easier and less socially risky to be critical of things, or non-committal, than to stand for a positive vision. It is easier to produce a valid criticism than an idea immune to valid criticism (and easier again to say, ‘this is very simplistic - the situation is subtle’). And if an idea is criticized, the critic gets to seem sophisticated, while the holder of the idea gets to seem naïve. A criticism is smaller than a positive vision, so a critic is usually not staking their reputation on their criticism as much, or claiming that it is good, in the way that the enthusiast is.
But there are also rewards for positive visions and for sincere enthusiasm that aren’t had by critics and routine doubters. So for things to change over time, you really just need the scale of these incentives to change, whether in a basic way or because the situation is changing.
One way this could have happened is that the internet (or even earlier change in the information economy) somehow changed the ecology of enthusiasts and doubters, pushing the incentives away from enthusiasm. e.g. The ease, convenience and anonymity of criticizing and doubting on the internet puts a given positive vision in contact with many more critics, making it basically impossible for an idea to emerge not substantially marred by doubt and teeming with uncertainties and summarizable as ‘maybe X, but I don’t know, it’s complicated’. This makes presenting positive visions less appealing, reducing the population of positive vision havers, and making them either less confident or more the kinds of people whose confidence isn’t affected by the volume of doubt other people might have about what they are saying. Which all make them even easier targets for criticism, and make confident enthusiasm for an idea increasingly correlated with being some kind of arrogant fool. Which decreases the basic respect offered by society for someone seeming to have a positive vision.
This is a very speculative story, but something like these kinds of dynamics seems plausible.
These thoughts were inspired by a conversation I had with Nick Beckstead.
-
In balance and flux
Someone more familiar with ecology recently noted to me that it used to be a popular view that nature was ‘in balance’ and had some equilibrium state, that it should be returned to. Whereas the new understanding is that there was never an equilibrium state. Natural systems are always changing. Another friend who works in natural management also recently told me that their role in the past might have been trying to restore things to their ‘natural state’, but now the goal was to prepare yourself for what your ecology was becoming. A brief Googling returns this National Geographic article by Tik Root, The ‘balance of nature’ is an enduring concept. But it’s wrong. along the same lines. In fairness, they seem to be arguing against both the idea that nature is in a balance so intense that you can easily disrupt it, and the idea that nature is in a balance so sturdy that it will correct anything you do to it, which sounds plausible. But they don’t say that ecosystems are probably in some kind of intermediately sturdy balance, in many dimensions at least. They say that nature is ‘in flux’ and that the notion of balance is a misconception.
It seems to me though that there is very often equilibrium in some dimensions, even in a system that is in motion in other dimensions, and that that balance can be very important to maintain.
Some examples:
- bicycle
- society with citizens with a variety of demeanors, undergoing broad social change
- human growing older, moving to Germany, and getting pregnant, while maintaining a narrow range of temperatures and blood concentrations of different chemicals
So the observation that a system is in flux seems fairly irrelevant to whether it is in equilibrium.
Any system designed to go somewhere relies on some of its parameters remaining within narrow windows. Nature isn’t designed to go somewhere, so the issue of what ‘should’ happen with it is non-obvious. But the fact that ecosystems always gradually change along some dimensions (e.g. grassland becoming forest) doesn’t seem to imply that there are not still balance in other dimensions, where they don’t change so much, and where changing is more liable to lead to very different and arguably less good states.
For instance, as a grassland gradually reforests, it might continue to have a large number of plant eating bugs, and bug-eating birds, such that the plant eating bugs would destroy the plants entirely if there were ever too many of them, but as there become more of them, the birds also flourish, and then eat them. As the forest grows, the tree-eating bugs become more common relative to the grass-eating bugs, but the rough equilibrium of plants, bugs, and birds remains. If the modern world was disrupting the reproduction of the birds, so that they were diminishing even while the bugs to eat were plentiful, threatening a bug-explosion-collapse in which the trees and grass would be destroyed by the brief insect plague, I think it would be reasonable to say that the modern world was disrupting the equilibrium, or putting nature out of balance.
The fact that your bike has been moving forward for miles doesn’t mean that leaning a foot to the left suddenly is meaningless, in systems terms.
-
What is going on in the world?
Here’s a list of alternative high level narratives about what is importantly going on in the world—the central plot, as it were—for the purpose of thinking about what role in a plot to take:
- The US is falling apart rapidly (on the scale of years), as evident in US politics departing from sanity and honor, sharp polarization, violent civil unrest, hopeless pandemic responses, ensuing economic catastrophe, one in a thousand Americans dying by infectious disease in 2020, and the abiding popularity of Trump in spite of it all.
- Western civilization is declining on the scale of half a century, as evidenced by its inability to build things it used to be able to build, and the ceasing of apparent economic acceleration toward a singularity.
- AI agents will control the future, and which ones we create is the only thing about our time that will matter in the long run. Major subplots:
- ‘Aligned’ AI is necessary for a non-doom outcome, and hard.
- Arms races worsen things a lot.
- The order of technologies matters a lot / who gets things first matters a lot, and many groups will develop or do things as a matter of local incentives, with no regard for the larger consequences.
- Seeing more clearly what’s going on ahead of time helps all efforts, especially in the very unclear and speculative circumstances (e.g. this has a decent chance of replacing subplots here with truer ones, moving large sections of AI-risk effort to better endeavors).
- The main task is finding levers that can be pulled at all.
- Bringing in people with energy to pull levers is where it’s at.
- Institutions could be way better across the board, and these are key to large numbers of people positively interacting, which is critical to the bounty of our times. Improvement could make a big difference to swathes of endeavors, and well-picked improvements would make a difference to endeavors that matter.
- Most people are suffering or drastically undershooting their potential, for tractable reasons.
- Most human effort is being wasted on endeavors with no abiding value.
- If we take anthropic reasoning and our observations about space seriously, we appear very likely to be in a ‘Great Filter’, which appears likely to kill us (and unlikely to be AI).
- Everyone is going to die, the way things stand.
- Most of the resources ever available are in space, not subject to property rights, and in danger of being ultimately had by the most effective stuff-grabbers. This could begin fairly soon in historical terms.
- Nothing we do matters for any of several reasons (moral non-realism, infinite ethics, living in a simulation, being a Boltzmann brain, ..?)
- There are vast quantum worlds that we are not considering in any of our dealings.
- There is a strong chance that we live in a simulation, making the relevance of each of our actions different from that which we assume.
- There is reason to think that acausal trade should be a major factor in what we do, long term, and we are not focusing on it much and ill prepared.
- Expected utility theory is the basis of our best understanding of how best to behave, and there is reason to think that it does not represent what we want. Namely, Pascal’s mugging, or the option of destroying the world with all but one in a trillion chance for a proportionately greater utopia, etc.
- Consciousness is a substantial component of what we care about, and we not only don’t understand it, but are frequently convinced that it is impossible to understand satisfactorily. At the same time, we are on the verge of creating things that are very likely conscious, and so being able to affect the set of conscious experiences in the world tremendously. Very little attention is being given to doing this well.
- We have weapons that could destroy civilization immediately, which are under the control of various not-perfectly-reliable people. We don’t have a strong guarantee of this not going badly.
- Biotechnology is advancing rapidly, and threatens to put extremely dangerous tools in the hands of personal labs, possibly bringing about a ‘vulnerable world’ scenario.
- Technology keeps advancing, and we may be in a vulnerable world scenario.
- The world is utterly full of un-internalized externalities and they are wrecking everything.
- There are lots of things to do in the world, we can only do a minuscule fraction, and we are hardly systematically evaluating them at all. Meanwhile massive well-intentioned efforts are going into doing things that are probably much less good than they could be.
- AI is powerful force for good, and if it doesn’t pose an existential risk, the earlier we make progress on it, the faster we can move to a world of unprecedented awesomeness, health and prosperity.
- There are risks to the future of humanity (‘existential risks’), and vastly more is at stake in these than in anything else going on (if we also include catastrophic trajectory changes). Meanwhile the world’s thinking and responsiveness to these risks is incredibly minor and they are taken unseriously.
- The world is controlled by governments, and really awesome governance seems to be scarce and terrible governance common. Yet we probably have a lot of academic theorizing on governance institutions, and a single excellent government based on scalable principles might have influence beyond its own state.
- The world is hiding, immobilized and wasted by a raging pandemic.
It’s a draft. What should I add? (If, in life, you’ve chosen among ways to improve the world, is there a simple story within which your choices make particular sense?)
-
Condition-directedness
In chess, you can’t play by picking a desired end of the game and backward chaining to the first move, because there are vastly more possible chains of moves than your brain can deal with, and the good ones are few. Instead, chess players steer by heuristic senses of the worth of situations. I assume they still back-chain a few moves (‘if I go there, she’ll have to move her rook, freeing my queen’) but just leading from a heuristically worse to a heuristically better situation a short hop away.
In life, it is often taken for granted that one should pursue goals, not just very locally, but over scales of decades. The alternative is taken to be being unambitious and directionless.
But there should also be an alternative that is equivalent to the chess one: heuristically improving the situation, without setting your eye on a particular pathway to a particular end-state.
Which seems like actually what people do a lot of the time. For instance, making your living room nice without a particular plan for it, or reading to be ‘well read’, or exercising to be ‘fit’ (at least insofar as having a nice living space and being fit and well-read are taken as generally promising situations rather than stepping stones immediately prior to some envisaged meeting, say). Even at a much higher level, spending a whole working life upholding the law or reporting on events or teaching the young because these put society in a better situation overall, not because they will lead to some very specific outcome.
In spite of its commonness, I’m not sure that I have heard of this type of action labeled as distinct from goal-directedness and undirectedness. I’ll call it condition-directedness for now. When people are asked for their five year plans, they become uncomfortable if they don’t have one, rather than proudly stating that they don’t currently subscribe to goal-oriented strategy at that scale. Maybe it’s just that I hang out in this strange Effective Altruist community, where all things are meant to be judged by their final measure on the goal, which perhaps encourages evaluating them explicitly with reference to an envisaged path to the goal, especially if it is otherwise hard to distinguish the valuable actions from doing whatever you feel like.
It seems like one could be condition-directed and yet very ambitious and not directionless. (Though your ambition would be non-specific, and your direction would be local, and maybe they are the worse for these things?) For instance, you might work tirelessly on whatever seems like it will improve the thriving of a community that you are part of, and always know in which direction you are pushing, and have no idea what you will be doing in five years.
Whether condition-directedness is a good kind of strategy would seem to depend on the game you are playing, and your resources for measuring and reasoning about it. In chess, condition-directedness seems necessary. Somehow longer term plans do seem more feasible in life than in chess though, so it is possible that they are always better in life, at the scales in question. I doubt this, especially given the observation that people often seem to be condition-directed, at least at some scales and in some parts of life.
(These thoughts currently seem confused to me - for instance, what is up with scales? How is my knowing that I do want to take the king relevant?)
Inspired by a conversation with John Salvatier.
-
Opposite attractions
Is the opposite of what you love also what you love?
I think there’s a general pattern where if you value A you tend to increase the amount of it in your life, and you end feeling very positively about various opposites of A—things that are very unlike A, or partially prevent A, or undo some of A’s consequences—as well. At least some of the time, or for some parts of you, or in some aspects, or when your situation changes a bit. Especially if you contain multitudes.
Examples:
- Alice values openness, so tends to be very open: she tells anyone who asks (and many people who don’t) what’s going on in her life, and writes about it abundantly on the internet. But when she is embarrassed about something, she feels oppressed by everyone being able to see her so easily. So then she hides in her room, works at night when nobody is awake to think of her, and writes nothing online. Because for her, interacting with someone basically equates to showing them everything, her love of openness comes with a secondary love of being totally alone in her room.
- Bob values connecting with people, and it seems hard in the modern world, but he practices heartfelt listening and looking people in the eye, and mentally jumping into their perspectives. He often has meaningful conversations in the grocery line, which he enjoys and is proud of. He goes to Burning Man and finds thousands of people desperate to connect with him, so that his normal behavior is quickly leading to an onslaught of connecting that is more than he wants. He finds himself savoring the impediments to connection—the end of an eye-gazing activity, the chance to duck out of a conversation, the walls of his tent—in a way that nobody else at Burning Man is.
- An extreme commitment to honesty and openness with your partner might leads to a secondary inclination away from honesty and openness with yourself.
- A person who loves travel also loves being at home again afterward, with a pointed passion absent from a person who is a perpetual homebody.
- A person who loves jumping in ice water is more likely to also love saunas than someone who doesn’t.
- A person who loves snow is more likely to love roaring fires.
- A person who loves walking has really enjoyed lying down at the end of the day.
- A person who surrounds themselves with systems loves total abandonment of them during holiday more than he who only had an appointment calendar and an alarm clock to begin with.
- A person with five children because they love children probably wants a babysitter for the evening more than the person who ambivalently had a single child.
- A person who loves hanging out with people who share an interest in the principles of effective altruism is often also especially excited to hang out with people who don’t, on the occasions when they do that.
- A person who directs most of their money to charity is more obsessed with the possibility of buying an expensive dress than their friend who cares less about charity.
- A person who is so drawn to their partner’s company that they can’t stay away from them at home sometimes gets more out of solitary travel than someone more solitariness-focused in general.
- A person craving danger also cares about confidence in safety mechanisms.
- A person who loves the sun wants sunglasses and sunscreen more than a person who stays indoors.
This pattern makes sense, because people and things are multifaceted, and effects are uncertain and delayed. So some aspect of you liking some aspect of a thing at some time will often mean you ramp up that kind of thing, producing effects other than the one you liked, plus more of the effect that you liked than intended because of delay. And anyway you are a somewhat different creature by then, and maybe always had parts less amenable to the desired thing anyway. Or more simply, because in systems full of negative feedbacks, effects tend to produce opposite effects, and you and the world are such systems.
-
What is it good for? But actually?
I didn’t learn about history very well prior to my thirties somehow, but lately I’ve been variously trying to rectify this. Lately I’ve been reading Howard Zinn’s People’s History of the United States, listening to Steven Pinker’s the Better Angels of Our Nature, watching Ken Burns and Lynn Novick’s documentary about the Vietnam War and watching Oversimplified history videos on YouTube (which I find too lighthearted for the subject matter, but if you want to squeeze extra history learning in your leisure and dessert time, compromises can be worth it.)
There is a basic feature of all this that I’m perpetually confused about: how has there been so much energy for going to war?
It’s hard to explain my confusion, because in each particular case, there might be plenty of plausible motives given–someone wants ‘power’, or to ‘reunite their country’, or there is some customary enemy, or that enemy might attack them otherwise–but overall, it seems like the kind of thing people should be extremely averse to, such that even if there were plausibly good justifications, they wouldn’t just win out constantly, other justifications for not doing the thing would usually be found. Like, there are great reasons for writing epic treatises on abstract topics, but somehow, most people find that they don’t get around to it. I expect going to some huge effort to travel overseas and die in the mud to be more like that, intuitively.
To be clear, I’m not confused here about people fighting in defense of things they care a lot about—joining the army when their country is under attack, or joining the Allies in WWII. And I’m not confused by people who are forced to fight, by conscription or desperate need of money. It’s just that across these various sources on history, I haven’t seen much comprehensible-to-me explanation of what’s going on in the minds of the people who volunteer to go to war (or take part in smaller dangerous violence) when the stakes aren’t already at the life or death level for them.
I am also not criticizing the people whose motives I am confused by–I’m confident that I’m missing things.
It’s like if I woke up tomorrow to find that half the country was volunteering to cut off their little finger for charity, I’d be pretty surprised. And if upon inquiring, each person had something to say—about how it was a good charity, or how suffering is brave and valiant, or how their Dad did it already, or how they were being emotionally manipulated by someone else who wanted it to happen, or they how wanted to be part of something—each one might not be that unlikely, but I’d still feel overall super confused, at a high level, at there being enough total energy behind this, given that it’s a pretty costly thing to do.
At first glance, the historical people heading off to war don’t feel surprising. But I feel like this is because it is taken for granted as what historical people do. Just as in stories about Christmas, it is taken for granted that Santa Clause will make and distribute billions of toys, because that’s what he does, even though his motives are actually fairly opaque. But historical people presumably had internal lives that would be recognizable to me. What did it look like from the inside, to hear that WWI was starting, and hurry to sign up? Or to volunteer for the French military in time to fight to maintain French control in Vietnam, in the First Indochina War, that preceded the Vietnam War?
I’d feel less surprised in a world where deadly conflict was more like cannibalism is in our world. Where yes, technically humans are edible, so if you are hungry enough you can eat them, but it is extremely rare for it to get to that, because nobody wants to be on any side of it, and they have very strong and consistent feelings about that, and if anyone really wanted to eat thousands or millions of people, say to bolster their personal or group power, it would be prohibitively expensive in terms of money or social capital to overcome the universal distaste for this idea.
-
Unexplored modes of language
English can be communicated via 2D symbols that can be drawn on paper using a hand and seen with eyes, or via sounds that can be made with a mouth and heard by ears.
These two forms are the same language because the mouth sounds and drawn symbols correspond at the level of words (and usually as far as sounds and letters, at least substantially). That is, if I write ‘ambition’, there is a specific mouth sound that you would use if converting it to spoken English, whereas if you were converting it to spoken French, there might not be a natural equivalent.
As far as I know, most popular languages are like this: they have a mouth-sound version and a hand-drawn (or hand-typed) version. They often have a braille version, with symbols that can be felt by touch instead of vision. An exception is sign languages (which are generally not just alternate versions of spoken languages), which use 4-D symbols gestured by hands over time, and received by eyes.
I wonder whether there are more modes of languages that it would be good to have. Would we have them, if there were? It’s not clear from a brief perusal of Wikipedia that Europe had sophisticated sign languages prior to about five hundred years ago. Communication methods generally have strong network effects—it’s not worth communicating by some method that nobody can understand, just like it’s not worth joining an empty dating site—and new physical modes of English are much more expensive than for instance new messaging platforms, and have nobody to promote them.
Uncommon modes of language that seem potentially good (an uninformed brainstorm):
- symbols drawn with hands on receiver’s skin, received by touch, I’ve heard of blind and deaf people such as Helen Keller using this, but it seems useful for instance when it is loud, or when you don’t want to be overheard or to annoy people nearby, or for covert communication under the table at a larger event, or for when you are wearing a giant face mask. -symbols gestured with whole body like interpretive dance, but with objective interpretation. Good from a distance, when loud, etc. Perhaps conducive to different sorts of expressiveness, like how verbal communication makes singing with lyrics possible, and there is complementarity between the words and the music.
- symbols gestured with whole body, interpreted by computer, received as written text What if keyboards were like a Kinect dance game? Instead of using your treadmill desk while you type with your hands, you just type with your arms, legs and body in a virtual reality whole-body keyboard space. Mostly good for exercise, non-sedentariness, feeling alive, etc.
- drumming/tapping, received by ears or touch possibly faster than spoken language, because precise sounds can be very fast. I don’t know. This doesn’t really sound good.
- a sign version of English this exists, but is rare. Good for when it is loud, when you don’t want to be overheard, when you are wearing a giant face mask or are opposed to exhaling too much on the other person, when you are at a distance, etc.
- symbols drawn with hands in one place e.g. the surface of a phone, or a small number of phone buttons, such that you could enter stuff on your phone by tapping your fingers in place in a comfortable position with the hand you were holding it with, preferably still in your pocket, rather than awkwardly moving them around on the surface while you hold it either with another hand or some non-moving parts of the same hand, and having to look at the screen while you do it. This could be combined with the first one on this list.
- What else?
Maybe if there’s a really good one, we could overcome the network effect with an assurance contract. (Or try to, and learn more about why assurance contracts aren’t used more.)
-
Why are delicious biscuits obscure?
I saw a picture of these biscuits (or cookies), and they looked very delicious. So much so that I took the uncharacteristic step of actually making them. They were indeed among the most delicious biscuits of which I am aware. And yet I don’t recall hearing of them before. This seems like a telling sign about something. (The capitalist machinery? Culture? Industrial food production constraints? The vagaries of individual enjoyment?)

Why doesn’t the market offer these delicious biscuits all over the place? Isn’t this just the kind of rival, excludable, information-available, well-internalized good that markets are on top of?
Some explanations that occur to me:
- I am wrong or unusual in my assessment of deliciousness, and for instance most people would find a chocolate chip cookie or an Oreo more delicious.
- They are harder to cook commercially than the ubiquitous biscuits for some reason. e.g. they are most delicious warm.
- They are Swedish, and there are mysterious cultural or linguistic barriers to foods spreading from their original homes. This would also help explain some other observations, to the extent that it counts as an explanation at all.
- Deliciousness is not a central factor in food spread. (Then what is?)
If you want to help investigate, you can do so by carrying out the following recipe and reporting on the percentile of deliciousness of the resulting biscuits. (I do not claim that this is a high priority investigation to take part in, unless you are hungry for delicious biscuits or a firsthand encounter with a moderately interesting sociological puzzle.)
*
Kolakakor
(Or Kolasnittar. Adapted from House & Garden’s account of a recipe in Magnus Nilsson’s “The Nordic Baking Book”. It’s quite plausible that their versions are better than mine, which has undergone pressure for ease plus some random ingredient substitutions. However I offer mine, since it is the one I can really vouch for.)
Takes about fifteen minutes of making, and fifteen further minutes of waiting. Makes enough biscuits for about five people to eat too many biscuits, plus a handful left over. (Other recipe calls it about 40 ‘shortbreads’)
Ingredients
- 200 g melted butter (e.g. microwave it)
- 180 g sugar
- 50 g golden syrup
- 50g honey
- 300 g flour, ideally King Arthur gluten free flour, but wheat flour will also do
- 1 teaspoon bicarbonate of soda (baking soda)
- 2 teaspoon ground ginger
- 2 good pinches of salt
Method
- Preheat oven: 175°C/345°F
- Put everything in a mixing bowl (if you have kitchen scales, put the mixing bowl on them, set scales to zero, add an ingredient, reset scales to zero, add the next ingredient, etc.)
- Mix.
- Taste [warning: public health officials say not to do this because eating raw flour is dangerous]. Adjust mixedness, saltiness, etc. It should be very roughly the consistency of peanut butter, i.e. probably less firm than you expect. (Taste more, as desired. Wonder why we cook biscuits at all. Consider rebellion. Consider Chesterton’s fence. Taste one more time.)
- Cover a big tray or a couple of small trays with baking paper.
- Make the dough into about four logs, around an inch in diameter, spaced several inches from one another and the edges of the paper. They can be misshapen; their shapes are temporary.
- Cook for about 15 minutes, or until golden and spread out into 1-4 giant flat seas of biscuit. When you take them out, they will be very soft and probably not appear to be cooked.
- As soon as they slightly cool and firm up enough to pick up, start chopping them into strips about 1.25 inches wide and eating them.
*
Bonus mystery: they are gluten free, egg free, and can probably easily be dairy free. The contest with common vegan and/or gluten free biscuit seems even more winnable, so why haven’t they even taken over that market?
-
Cultural accumulation
When I think of humans being so smart due to ‘cultural accumulation’, I think of lots of tiny innovations in thought and technology being made by different people, and added to the interpersonal currents of culture that wash into each person’s brain, leaving a twenty year old in 2020 much better intellectually equipped than a 90 year old who spent their whole life thinking in 1200 AD.
This morning I was chatting to my boyfriend about whether a person who went back in time (let’s say a thousand years) would be able to gather more social power than they can now in their own time. Some folk we know were discussing the claim that some humans would have a shot at literally take over the world if sent back in time, and we found this implausible.
The most obvious differences between a 2020 person and a 1200 AD person, in 1200 AD, is that they have experience with incredible technological advances that the 1200 AD native doesn’t even know are possible. But a notable thing about a modern person is that they famously don’t know what a bicycle looks like, so the level of technology they might be able to actually rebuild on short notice in 1200 AD is probably not at the level of a nutcracker, and they probably already had those in 1200 AD.
How does 2020 have complicated technology, if most people don’t know how it works? One big part is specialization: across the world, quite a few people do know what bicycles look like. And more to the point, presumably some of them know in great detail what bicycle chains look like, and what they are made of, and what happens if you make them out of slightly different materials or in slightly different shapes, and how such things interact with the functioning of the bicycle.
But suppose the 2020 person who is sent back is a bicycle expert, and regularly builds their own at home. Can they introduce bikes to the world 600 years early? My tentative guess is yes, but not very ridable ones, because they don’t have machines for making bike parts, or any idea what those machines are like or the principles behind them. They can probably demonstrate the idea of a bike with wood and cast iron and leather, supposing others are cooperative with various iron casting, wood shaping, leather-making know-how. But can they make a bike that is worth paying for and riding?
I’m not sure, and bikes were selected here for being so simple that an average person might know what their machinery looks like. Which makes them unusually close among technologies to simple chunks of metal. I don’t think a microwave oven engineer can introduce microwave ovens in 1200, or a silicon chip engineer can make much progress on introducing silicon chips. These require other technologies that require other technologies too many layers back.
But what if the whole of 2020 society was transported to 1200? The metal extruding experts and the electricity experts and the factory construction experts and Elon Musk? Could they just jump back to 2020 levels of technology, since they know everything relevant between them? (Assuming they are somehow as well coordinated in this project as they are in 2020, and are not just putting all of their personal efforts into avoiding being burned at the stake or randomly tortured in the streets.)
A big way this might fail is if 2020 society knows everything between them needed to use 2020 artifacts to get more 2020 artifacts, but don’t know how to use 1200 artifacts to get 2020 artifacts.
On that story, the 1200 people might start out knowing methods for making c. 1200 artifacts using c. 1200 artifacts, but they accumulate between them the ideas to get them to c. 1220 artifacts with the c. 1200 artifacts, which they use to actually create those new artifacts. They pass to their children this collection of c. 1220 artifacts and the ideas needed to use those artifacts to get more c. 1220 artifacts. But the new c. 1220 artifacts and methods replaced some of the old c. 1200 artifacts and methods. So the knowledge passed on doesn’t include how to use those obsoleted artifacts to create the new artifacts, or the knowledge about how to make the obsoleted artifacts. And the artifacts passed on don’t include the obsoleted ones. If this happens every generation for a thousand years, the cultural inheritance received by the 2020 generation includes some highly improved artifacts plus the knowledge about how to use them, but not necessarily any record of the path that got there from prehistory, or of the tools that made the tools that made the tools that made these artifacts.
This differs from my first impression of ‘cultural accumulation’ in that:
- physical artifacts are central to the process: a lot of the accumulation is happening inside them, rather than in memetic space.
- humanity is not accumulating all of the ideas it has come up with so far, even the important ones. It is accumulating something more like a best set of instructions for the current situation, and throwing a lot out as it goes.
Is this is how things are, or is my first impression more true?
-
Misalignment and misuse: whose values are manifest?
AI related disasters are often categorized as involving misaligned AI, or misuse, or accident. Where:
- misuse means the bad outcomes were wanted by the people involved,
- misalignment means the bad outcomes were wanted by AI (and not by its human creators), and
- accident means that the bad outcomes were not wanted by those in power but happened anyway due to error.
In thinking about specific scenarios, these concepts seem less helpful.
I think a likely scenario leading to bad outcomes is that AI can be made which gives a set of people things they want, at the expense of future or distant resources that the relevant people do not care about or do not own.
For example, consider autonomous business strategizing AI systems that are profitable additions to many companies, but in the long run accrue resources and influence and really just want certain businesses to nominally succeed, resulting in a worthless future. Suppose Bob is considering whether to get a business strategizing AI for his business. It will make the difference between his business thriving and struggling, which will change his life. He suspects that within several hundred years, if this sort of thing continues, the AI systems will control everything. Bob probably doesn’t hesitate, in the way that businesses don’t hesitate to use gas vehicles even if the people involved genuinely think that climate change will be a massive catastrophe in hundreds of years.
When the business strategizing AI systems finally plough all of the resources in the universe into a host of thriving 21st Century businesses, was this misuse or misalignment or accident? The strange new values that were satisfied were those of the AI systems, but the entire outcome only happened because people like Bob chose it knowingly (let’s say). Bob liked it more than the long glorious human future where his business was less good. That sounds like misuse. Yet also in a system of many people, letting this decision fall to Bob may well have been an accident on the part of others, such as the technology’s makers or legislators.
Outcomes are the result of the interplay of choices, driven by different values. Thus it isn’t necessarily sensical to think of them as flowing from one entity’s values or another’s. Here, AI technology created a better option for both Bob and some newly-minted misaligned AI values that it also created—‘Bob has a great business, AI gets the future’—and that option was worse for the rest of the world. They chose it together, and the choice needed both Bob to be a misuser and the AI to be misaligned. But this isn’t a weird corner case, this is a natural way for the future to be destroyed in an economy.
Thanks to Joe Carlsmith for conversation leading to this post.
-
Tweet markets for impersonal truth tracking?
Should social media label statements as false, misleading or contested?
Let’s approach it from the perspective of what would make the world best, rather than e.g. what rights do the social media companies have, as owners of the social media companies.
The basic upside seems to be that pragmatically, people share all kinds of false things on social media, and that leads to badness, and this slows that down.
The basic problem with it is that maybe we can’t distinguish worlds where social media companies label false things as false, and those where they label things they don’t like as false, or things that aren’t endorsed by other ‘official’ entities. So maybe we don’t want such companies to have the job of deciding what is considered true or false, because a) we don’t trust them enough to give them this sacred and highly pressured job forever, or b) we don’t expect everyone to trust them forever, and it would be nice to have better recourse when disagreement appears than ‘but I believe them’.
If there were a way to systematically inhibit or label false content based on its falseness directly, rather than via a person’s judgment, that would be an interesting solution that perhaps everyone reasonable would agree to add. If prediction markets were way more ubiquitous, each contentious propositional Tweet could say under it the market odds for the claim.
Or what if Twitter itself were a prediction market, trading in Twitter visibility? For just-posted Tweets, instead of liking them, you can bet your own cred on them. Then a while later, they are shown again and people can vote on whether they turned out right and you win or lose cred. Then your total cred determines how much visibility your own Tweets get.
It seems like this would solve:
- the problem for prediction markets where it is illegal to bet money and hard to be excited about fake money
- the problem for prediction markets where it’s annoying to go somewhere to predict things when you are doing something else, like looking at Twitter
- the problem for Twitter where it is full of fake claims
- the problem for Twitter users where they have to listen to fake claims all the time, and worry about whether all kinds of things are true or not
It would be pretty imperfect, since it throws the gavel to future Twitter users, but perhaps they are an improvement on the status quo, or on the status quo without the social media platforms themselves making judgments.
-
Automated intelligence is not AI
Sometimes we think of ‘artificial intelligence’ as whatever technology ultimately automates human cognitive labor.
I question this equivalence, looking at past automation. In practice human cognitive labor is replaced by things that don’t seem at all cognitive, or like what we otherwise mean by AI.
Some examples:
- Early in the existence of bread, it might have been toasted by someone holding it close to a fire and repeatedly observing it and recognizing its level of doneness and adjusting. Now we have machines that hold the bread exactly the right distance away from a predictable heat source for a perfect amount of time. You could say that the shape of the object embodies a lot of intelligence, or that intelligence went into creating this ideal but non-intelligent tool.
- Self-cleaning ovens replace humans cleaning ovens. Humans clean ovens with a lot of thought—looking at and identifying different materials and forming and following plans to remove some of them. Ovens clean themselves by getting very hot.
- Carving a rabbit out of chocolate takes knowledge of a rabbit’s details, along with knowledge of how to move your hands to translate such details into chocolate with a knife. A rabbit mold automates this work, and while this route may still involve intelligence in the melting and pouring of the chocolate, all rabbit knowledge is now implicit in the shape of the tool, though I think nobody would call a rabbit-shaped tin ‘artificial intelligence’.
- Human pouring of orange juice into glasses involves various mental skills. For instance, classifying orange juice and glasses and judging how they relate to one another in space, and moving them while keeping an eye on this. Automatic orange juice pouring involves for instance a button that can only be pressed with a glass when the glass is in a narrow range of locations, which opens an orange juice faucet running into a spot common to all the possible glass-locations.
Some of this is that humans use intelligence where they can use some other resource, because it is cheap on the margin where the other resource is expensive. For instance, to get toast, you could just leave a lot of bread at different distances then eat the one that is good. That is bread-expensive and human-intelligence-cheap (once you come up with the plan at least). But humans had lots of intelligence and not much bread. And if later we automate a task like this, before we have computers that can act very similarly to brains, then the alternate procedure will tend to be one that replaces human thought with something that actually is cheap at the time, such as metal.
I think a lot of this is that to deal with a given problem you can either use flexible intelligence in the moment, or you can have an inflexible system that happens to be just what you need. Often you will start out using the flexible intelligence, because being flexible it is useful for lots of things, so you have some sitting around for everything, whereas you don’t have an inflexible system that happens to be just what you need. But if a problem seems to be happening a lot, it can become worth investing the up-front cost of getting the ideal tool, to free up your flexible intelligence again.
-
Whence the symptoms of social media?
A thing I liked about The Social Dilemma was the evocative image of oneself being in an epic contest for one’s attention with a massive and sophisticated data-nourished machine, tended by teams of manipulation experts. The hopelessness of the usual strategies—like spur-of-the-moment deciding to ‘try to use social media less’—in the face of such power seems clear.
But another question I have is whether this basic story of our situation—that powerful forces are fluently manipulating our behavior—is true.
Some contrary observations from my own life:
- The phenomenon of spending way too long doing apparently pointless things on my phone seems to be at least as often caused by things that are not massively honed to manipulate me. For instance, I recently play a lot of nonograms, a kind of visual logic puzzle that was invented by two people independently in the 80s and which I play in one of many somewhat awkward-to-use phone apps, I assume made by small teams mostly focused on making the app work smoothly. My sense is that if I didn’t have nonograms style games or social media or news to scroll through, then I would still often idly pick up my phone and draw, or read books, or learn Spanish, or memorize geographic facts, or scroll through just anything on offer to scroll through (I also do these kinds of things already). So my guess is that it is my phone’s responsiveness and portability and tendency to do complicated things if you press buttons on it, that makes it a risk for time consumption. Facebook’s efforts to grab my attention probably don’t hurt, but I don’t feel like they are most of the explanation for phone-overuse in my own life.
- Notifications seem clumsy and costly. They do grab my attention pretty straightforwardly, but this strategy appears to have about the sophistication of going up to someone and tapping them on the shoulder continually, when you have a sufficiently valuable relationship that they can’t just break it off you annoy them too much. In that case it isn’t some genius manipulation technique, it’s just burning through the goodwill the services have gathered by being valuable in other ways. If I get unnecessary notifications, I am often annoyed and try to stop them or destroy the thing causing them.
- I do often scroll through feeds for longer than I might have planned to, but the same goes for non-manipulatively-honed feeds. For instance when I do a Google Image search for skin infections, or open some random report and forget why I’m looking at it. So I think scrolling down things might be a pretty natural behavior for things that haven’t finished yet, and are interesting at all (but maybe not so interesting that one is, you know, awake..)1
- A thing that feels attractive about Facebook is that one wants to look at things that other people are looking at. (Thus for instance reading books and blog posts that just came out over older, better ones.) Social media have this, but presumably not much more than newspapers did before, since a greater fraction of the world was looking at the same newspaper before.
In sum, I offer the alternate theory that various technology companies have combined:
- pinging people
- about things they are at least somewhat interested in
- that everyone is looking at
- situated in an indefinite scroll
- on a responsive, detailed pocket button-box
…and that most of the attention-suck and influence that we see is about those things, not about the hidden algorithmic optimizing forces that Facebook might have.
(Part 1 of Social Dilemma review)
-
My boyfriend offers alternate theory, that my scrolling instinct comes from Facebook. ↩
-
But what kinds of puppets are we?
I watched The Social Dilemma last night. I took the problem that it warned of to be the following:
- Social media and similar online services make their money by selling your attention to advertisers
- These companies put vast optimization effort into manipulating you, to extract more attention
- This means your behavior and attention is probably very shaped by these forces (which you can perhaps confirm by noting your own readiness to scroll through stuff on your phone)
This seems broadly plausible and bad, but I wonder if it isn’t quite that bad.
I heard the film as suggesting that your behavior and thoughts in general are being twisted by these forces. But lets distinguish between a system where huge resources are going into keeping you scrolling say—at which point an advertiser will pay for their shot at persuading you—and a system where those resources are going into manipulating you directly to do the things that the advertiser would like. In the first case, maybe you look at your phone too much, but there isn’t a clear pressure on your opinions or behavior besides pro phone. In the second case, maybe you end up with whatever opinions and actions someone paid the most for (this all supposing the system works). Let’s call these distorted-looking and distorted-acting.
While watching I interpreted the film suggesting the sort of broad manipulation that would come with distorted-acting, but thinking about it afterwards, isn’t the kind of optimization going on with social media actually distorted-looking? (Followed by whatever optimization the advertisers do to get you to do what they want, which I guess is of a kind with what they have always done, so at least not a new experimental horror.) I actually don’t really know. And maybe it isn’t a bright distinction.
Maybe optimization for you clicking on ads should be a different category (i.e. ‘distorted-clicking’). This seems close to distorted-looking, in that it isn’t directly seeking to manipulate your behavior outside of your phone session, but a big step closer to distorted-acting, since you have been set off toward whatever you have ultimately been targeted to buy.
I was at first thinking that distorted-looking was safer than distorted-acting. But distorted-looking forces probably do also distort your opinions and actions. For instance, as the film suggested, you are likely to look more if you get interested in something that there is a lot of content on, or something that upsets you and traps your attention.
I could imagine distorted-looking actually being worse than distorted-acting: when your opinion can be bought, the change in it is presumably what someone would want. Whereas when your opinion is manipulated as a weird side effect of someone trying to get you to look more, then it could be any random thing, which might be terrible.(Or would there be such weird side effects in both cases anyway?)
-
Yet another world spirit sock puppet
I have almost successfully made and made decent this here my new blog, in spite of little pre-existing familiarity with relevant tools beyond things like persistence in the face of adversity and Googling things. I don’t fully understand how it works, but it is a different and freer non-understanding than with Wordpress or Tumblr. This blog is more mine to have mis-built and to go back and fix. It is like not understanding why your cake is still a liquid rather than like not understanding why your printer isn’t recognized by your computer.
My plan is to blog at worldspiritsockpuppet.com now, and cross-post to my older blogs the subset of posts that fit there.
The main remaining thing is to add comments. If anyone has views about how those should be, er, tweet at me?
-
The bads of ads
In London at the start of the year, perhaps there was more advertising than there usually is in my life, because I found its presence disgusting and upsetting. Could I not use public transport without having my mind intruded upon continually by trite performative questions?

Sometimes I fantasize about a future where stealing someone’s attention to suggest for the fourteenth time that they watch your awful-looking play is rightly looked upon as akin to picking their pocket.
Stepping back, advertising is widely found to be a distasteful activity. But I think it is helpful to distinguish the different unpleasant flavors potentially involved (and often not involved—there is good advertising):
-
Mind manipulation: Advertising is famous for uncooperatively manipulating people’s beliefs and values in whatever way makes them more likely to pay money somehow. For instance, deceptively encouraging the belief that everyone uses a certain product, or trying to spark unwanted wants.

-
Zero-sumness: To the extent advertising is aimed at raising the name recognition and thus market share of one product over its similar rivals, it is zero or negative sum: burning effort on both sides and the attention of the customer for no overall value.


-
Theft of a precious thing: Attention is arguably one of the best things you have, and its protection arguably worthy of great effort. In cases where it is vulnerable—for instance because you are outside and so do not personally control everything you might look at or hear—advertising is the shameless snatching of it. This might be naively done, in the same way that a person may naively steal silverware assuming that it is theirs to take because nothing is stopping them.

-
Cultural poison: Culture and the common consciousness are an organic dance of the multitude of voices and experiences in society. In the name of advertising, huge amounts of effort and money flow into amplifying fake voices, designed to warp perceptions–and therefore the shared world–to ready them for exploitation. Advertising can be a large fraction of the voices a person hears. It can draw social creatures into its thin world. And in this way, it goes beyond manipulating the minds of those who listen to it. Through those minds it can warp the whole shared world, even for those who don’t listen firsthand. Advertising shifts your conception of what you can do, and what other people are doing, and what you should pay attention to. It presents role models, designed entirely for someone else’s profit. It saturates the central gathering places with inanity, as long as that might sell something.

-
Market failure: Ideally, whoever my attention is worth most to would get it, regardless of whether it was initially stolen. For instance, if I have better uses for my attention than advertising, hopefully I will pay more to have it back than the advertiser expects to make by advertising to me. So we will be able to make a trade, and I’ll get my attention back. In practice this is probably too complicated, since so many tiny transactions are needed. E.g. the best message for me to see, if I have to see a message, when sitting on a train, is probably something fairly different from what I do see. It is also probably worth me paying a small sum to each person who would advertise at me to just see a blank wall instead. But it is hard for them to collect that money from each person. And in cases where the advertiser was just a random attention thief and didn’t have some special right to my attention, if I were to pay one to leave me alone, another one might immediately replace them.1

-
Ugliness: At the object level, advertising is often clearly detracting from the beauty of a place.

These aren’t necessarily distinct—to the extent ugliness is bad, say, one might expect that it is related to some market failure. But they are different reasons for disliking a thing-a person can hate something ugly while having no strong view on the perfection of ideal markets.
What would good and ethical advertising look like? Maybe I decide that I want to be advertised to now, and go to my preferred advertising venue. I see a series of beautiful messages about things that are actively helpful for me to know. I can downvote ads if I don’t like the picture of the world that they are feeding into my brain, or the apparent uncooperativeness of their message. I leave advertising time feeling inspired and happy.

Images: London Underground: Mona Eendra, painting ads: Megan Markham, Nescafe ad: Ketut Subiyanto, Coca-Cola: Hamish Weir, London Underground again: Willam Santos, figures in shade under ad: David Geib, Clear ad in train: Life of Wu, Piccadilly Circus: Negative Space, Building a new story: Wilhelm Gunkel.
-
For advertising in specific public locations, I could in principle pay by buying up the billboard or whatever and leaving it blank. ↩
-
EVERYTHING — WORLDLY POSITIONS — METEUPHORIC







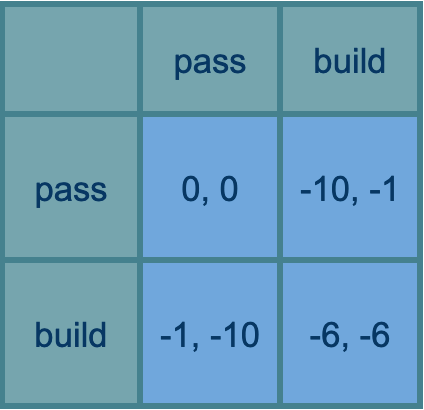








{kind=link}